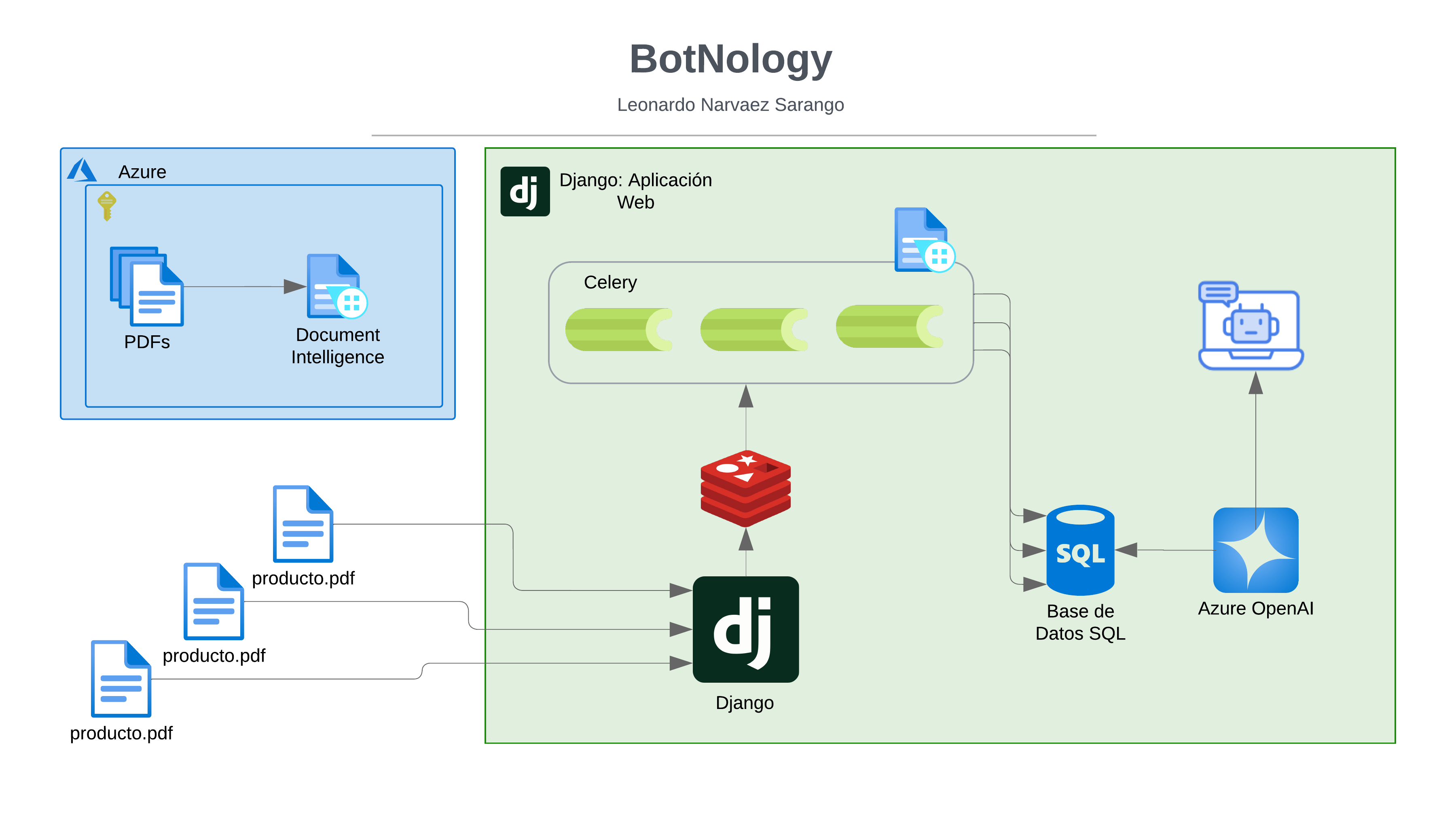
Introducción
En esta práctica de Databricks nos centraremos en los RDDs (Resilient Distributed Datasets), un componente fundamental de Apache Spark, que permiten la manipulación distribuida de grandes volúmenes de datos en un entorno paralelo. Los RDDs son una de las estructuras de datos más poderosas de Spark y permiten realizar operaciones de transformación y acción de manera eficiente.
Durante esta práctica, exploraremos cómo crear y manipular RDDs en Spark utilizando transformaciones y acciones. Las transformaciones son operaciones como map, filter, y flatMap, que devuelven un nuevo RDD a partir de otro sin modificar el original. Por otro lado, las acciones como collect, count o reduce producen un valor final o efectos colaterales (como guardar resultados en almacenamiento).
A lo largo de este ejercicio, trabajaremos con un dataset de vuelos, donde realizaremos diversas operaciones para limpiar, transformar y analizar los datos de retrasos en los vuelos. Además, también veremos cómo optimizar algunas de estas transformaciones utilizando técnicas propias de Spark.
Este proyecto te permitirá entender en profundidad cómo utilizar RDDs para manejar grandes volúmenes de datos, así como mejorar tu capacidad de análisis de datos en Databricks.
Objetivos
- Crear y manipular RDDs en Databricks.
- Realizar transformaciones y acciones básicas sobre RDDs.
- Analizar un dataset de vuelos (por ejemplo, retrasos de vuelos) utilizando RDDs.
- Visualizar los resultados de las transformaciones y análisis.
Configuración del Entorno en Databricks
Para ejecutar los notebooks y trabajar con los datos, es necesario tener un Cluster en Databricks. Si no sabes cómo configurar uno, te recomiendo que sigas esta guía completa de instalación y configuración de clusters en Databricks, (hasta paso 2) donde encontrarás instrucciones detalladas para crear y configurar tu cluster.
Subir el Dataset a Databricks
Para poder trabajar con los datos, primero necesitamos cargarlos en Databricks. Para cargar los archivos en Databricks, sigue estos pasos:
- Ve a workspace y luego agregamos los archivos que clonamos dentro de DBFS
 Pruebas:
Pruebas:
A partir de ahí, podrás comenzar a ejecutar las celdas del notebook para practicar con las transformaciones y acciones en los RDDs. Si eres nuevo en Spark, puedes realizar las pruebas paso a paso para familiarizarte con las distintas operaciones que puedes hacer sobre los RDDs.

Soluciones
En la carpeta solutions de este repositorio, encontrarás las soluciones completas para cada ejercicio propuesto. Aunque te invito a que intentes resolver los problemas por tu cuenta antes de ver las soluciones, ya que esto te ayudará a reforzar el aprendizaje y a comprender mejor cómo funcionan las transformaciones y acciones en Spark.
Este proyecto está diseñado para ayudarte a comprender cómo manejar grandes volúmenes de datos en un entorno distribuido, optimizando el proceso y aplicando técnicas de análisis de datos con PySpark y RDDs.