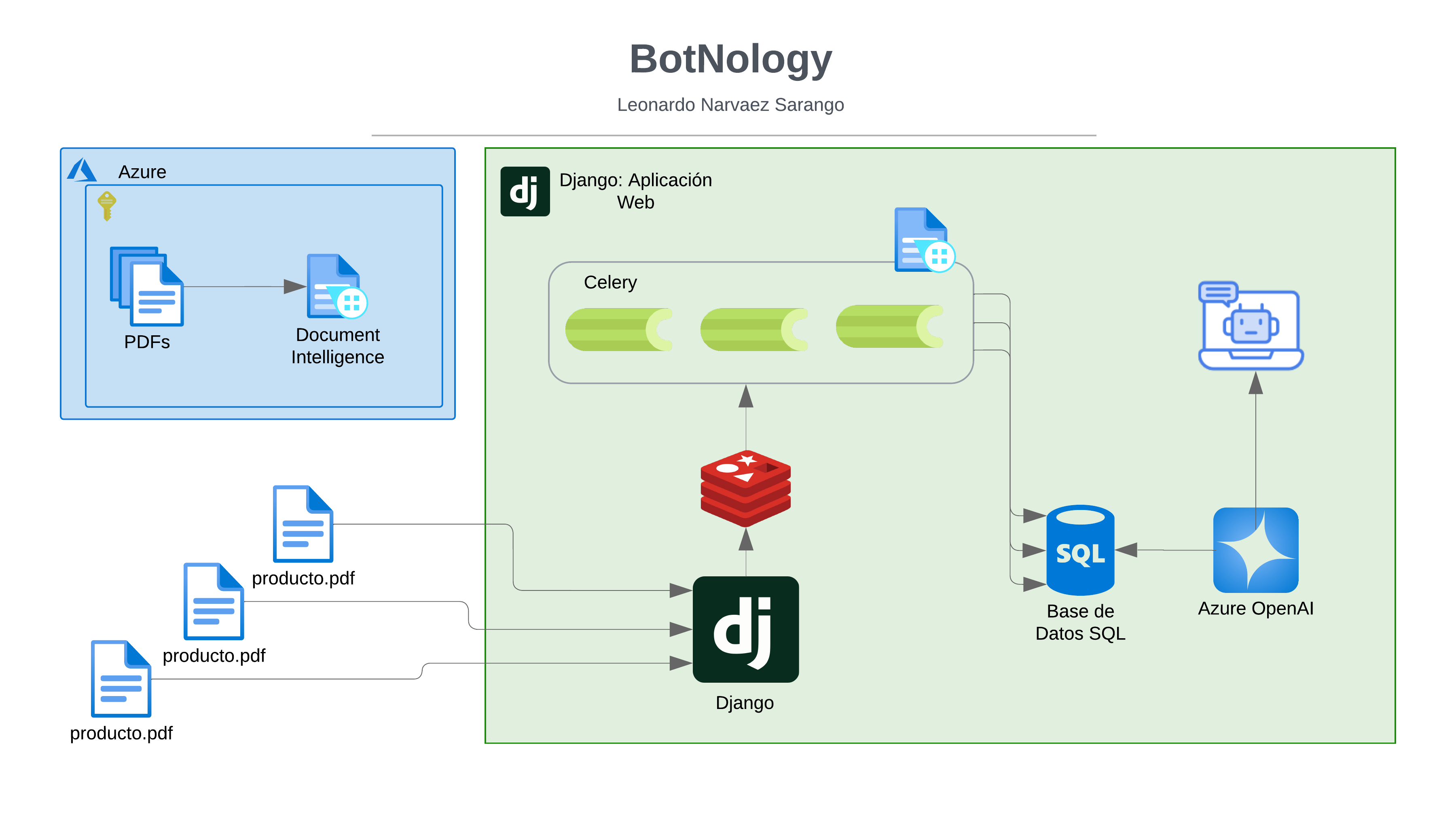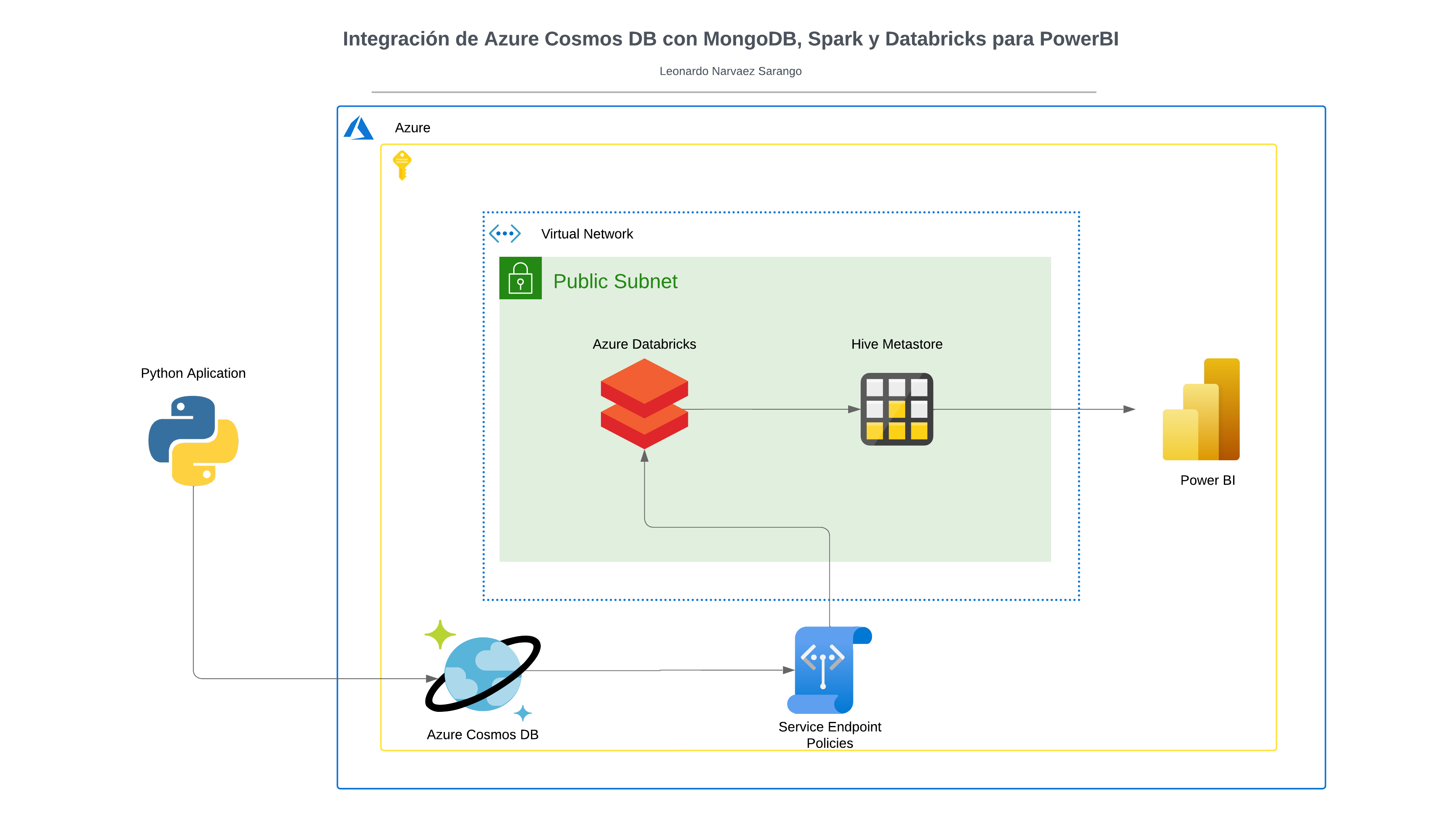
Introducción
Este proyecto de análisis del clima tiene como objetivo capturar datos meteorológicos utilizando la API de OpenWeather, almacenarlos en Cosmos DB y analizarlos mediante Azure Databricks y Power BI para generar visualizaciones útiles. Al proporcionar una experiencia práctica con la recolección, almacenamiento, procesamiento y visualización de datos en un entorno de nube, este proyecto facilita el estudio de los conceptos clave de análisis de datos y permite adquirir habilidades prácticas con herramientas populares en la industria, esenciales para el rol de analista de datos.
Integración:
En esta sección, detallaremos el proceso paso a paso para la integración de diversas tecnologías y herramientas. Desde la configuración inicial de los recursos en Azure hasta la creación de visualizaciones en Power BI, cada paso está diseñado para construir un flujo de trabajo robusto y eficiente que permita la captura, almacenamiento, procesamiento y análisis de datos meteorológicos. Siguiendo este guía, podrás implementar un sistema completo que integra datos en tiempo real y facilita su análisis, proporcionándote una experiencia práctica y valiosa en el uso de tecnologías esenciales para un analista de datos.
En el repositorio de GitHub https://github.com/leo-narvaez/cosmosdb-api-databricks, encontrarás los siguientes recursos necesarios para el proyecto:
- Script de Python (
weather_to_cosmo_db.py): Este script se utiliza para capturar datos meteorológicos de la API de OpenWeather y almacenarlos en Azure Cosmos DB. - Archivo de Requerimientos (
requirements.txt): Contiene las bibliotecas y dependencias necesarias para ejecutar el script de Python. - Notebooks de Databricks (
notebook/): Contienen los notebooks que se utilizan para cargar y procesar los datos almacenados en Cosmos DB. - Archivos de Imágenes (
images/): Carpeta para guardar las imágenes generadas durante el proyecto. - Archivos de Power BI (
powerbi/): Contienen los archivos generados de Power BI para la visualización de datos.
Configuración de Azure
Si aún no tienes una cuenta, dirígete a la página de inicio de Azure y regístrate para crear una cuenta gratuita. En nuestro caso, vamos a utilizar una cuenta estudiantil, lo cual ofrece beneficios adicionales como créditos gratuitos y acceso a varias herramientas y servicios de Azure sin costo. Esta opción es ideal para estudiantes que desean aprender y experimentar con los servicios en la nube de Azure, ya que proporciona un entorno completo para desarrollar y probar proyectos sin incurrir en gastos adicionales. Asegúrate de utilizar tu dirección de correo electrónico institucional durante el registro para aprovechar estos beneficios.
Configurar un nuevo grupo de recursos:
En el portal de Azure, ve a "Grupos de recursos" y haz clic en "Agregar". Dale un nombre a tu grupo de recursos y selecciona su ubicación. Este grupo contendrá todos los recursos necesarios para tu proyecto.

Crear una instancia de Cosmos DB:
En el portal de Azure, busca "Cosmos DB" y selecciona "Crear" para configurar una nueva base de datos. Elige la API para MongoDB y configura los parámetros necesarios, como el nombre de la base de datos, la clave de la base de datos y la colección.








Crear la Base de Datos:
Una vez creada la instancia de Cosmos DB, accede al recurso. En la sección "Explorador de Datos", selecciona la opción para crear una nueva Base de Datos. Asigna el nombre testingcosmosdb01 a esta nueva base de datos.


Crear la Colección:
Después de crear la base de datos, crea una nueva colección dentro de esta. Asigna el nombre pruebadatabrickscosmosdb a la colección. Esta colección se utilizará para almacenar los datos meteorológicos que se capturarán desde la API de OpenWeather.


Una vez creado se verá de la siguiente manera:

Obtener la API Key de OpenWeather:
Regístrate en el sitio web de OpenWeather y obtén una clave de API para acceder a los datos meteorológicos.

Obtener la Cadena de Conexión en Azure Cosmos DB
- Acceder a la Cadena de Conexión: En el portal de Azure, ve a tu recurso de Cosmos DB que creaste anteriormente.
- Buscar la Cadena de Conexión: Dentro de tu recurso de Cosmos DB, navega a la sección "Cadena de conexión" en el menú lateral.
- Copiar la Cadena de Conexión Principal: En la sección de Cadena de Conexión, busca el campo etiquetado como Cadena de Conexión Principal. Copia esta cadena, ya que la necesitarás para conectar tu script de Python a la base de datos Cosmos DB.
- Guardar la Cadena de Conexión: Guarda esta cadena en un lugar seguro, como un archivo de configuración o un gestor de secretos, para usarla en tu script
weather_to_cosmo_db.py.

Configuración del Script Local
- Copia de las Keys: Una vez hayas copiado las Keys desde la cadena de conexión de Azure Cosmos DB, reemplázalas en las líneas correspondientes del archivo
weather_to_cosmo_db.py. - Preparación del Entorno Local: Abre una terminal en tu máquina local y sigue estos pasos para configurar el entorno virtual y ejecutar el script.
Crear un Entorno Virtual:
python -m venv myenv
Activar el Entorno Virtual:
- En Linux/Mac:
source myenv/bin/activate
- En Windows:
myenv\Scripts\activate
Instalar los Requerimientos:
pip install -r script/requirements.txt
Actualizar las Credenciales en el Script:
- Abre el archivo
weather_to_cosmo_db.pyy reemplaza las líneas correspondientes con las Keys y la cadena de conexión que copiaste anteriormente.
Ejecutar el Script:
- Una vez que hayas actualizado las credenciales, ejecuta el script para guardar los datos climáticos en Azure Cosmos DB:
python script/weather_to_cosmo_db.py
Contenido del script:
from pymongo import MongoClient
import requests
import json
import time
# Configuración de OpenWeather API
API_KEY = "<KEY OPENWEATHER>" # Reemplaza con tu API Key
CITY = "Toronto" # Cambia por la ciudad deseada
WEATHER_URL = f"http://api.openweathermap.org/data/2.5/weather?q={CITY}&appid={API_KEY}&units=metric"
# Configuración de Cosmos DB
DB_NAME = "testingcosmosdb01" # Nombre de tu base de datos
COLLECTION_NAME = "pruebadatabrickcosmosdb" # Nombre de tu colección
CONNECTION = "<CADENA DE CONEXIÓN PRICIPAL>" # Conexión a Cosmos DB
# Función para insertar datos en Cosmos DB
def insert_weather_data(client, data):
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
document_id = collection.insert_one(data).inserted_id
print(f"Documento insertado con _id: {document_id}")
# Función para obtener datos meteorológicos
def get_weather_data():
try:
response = requests.get(WEATHER_URL)
if response.status_code == 200:
weather_data = response.json()
# Formatear los datos
formatted_data = {
"city": weather_data["name"],
"temperature": weather_data["main"]["temp"],
"weather": weather_data["weather"][0]["description"],
"humidity": weather_data["main"]["humidity"],
"pressure": weather_data["main"]["pressure"],
"wind_speed": weather_data["wind"]["speed"],
"timestamp": time.strftime('%Y-%m-%d %H:%M:%S')
}
return formatted_data
else:
print(f"Error al obtener los datos: {response.status_code}")
return None
except Exception as e:
print(f"Error al conectar con la API: {e}")
return None
# Bucle infinito para recopilar e insertar datos
while True:
client = MongoClient(CONNECTION)
weather_data = get_weather_data()
if weather_data:
print("Datos obtenidos del clima:")
print(weather_data)
insert_weather_data(client, weather_data)
print("Datos insertados exitosamente en Cosmos DB")
else:
print("No se pudieron obtener los datos del clima.")
# Pausa entre iteraciones (5 minutos)
time.sleep(20)
Cuando ejecutes en tu local, te mostrará un mensaje como este.

Ahora comprobamos si se ha insertado dentro de nuestro CosmosDB

Si dejas ejecutanto el script, se seguirá guardando datos, para terminar la ejecución pulsa CTRL + C.

Configurar redes virtuales y subredes:
En el portal de Azure, busca "Redes virtuales" y selecciona "Crear" para configurar una nueva red virtual. Define el nombre, la ubicación y la subred según tus necesidades.

Y creamos con la siguiente configuración:





Vamos al recurso y luego en Configuración > Espacio de direcciones y agregamos la dirección IP para Databricks

Azure Databricks
En el portal de Azure, busca "Azure Databricks" y selecciona "Crear" para configurar un nuevo clúster de Databricks. Configura el tamaño del clúster y la región según tus necesidades.

Usamos esta configuración:




Validamos y creamos

Subredes
Vamos a nuestra Red que creamos anteriormente y dentro de Subredes, se enlistan las redes creadas con la configuración de Databricks.
En la Red Pública vamos a crear un Service Endpoint para CosmosDB

En la sección de Puntos de Conexión del servicio agrega CosmoDB y guarda.

Área de trabajo de Azure Databricks

Creamos el Clúster

Usa esta configuración:

En opciones avanzadas, pega en la configuración de Spark esta sección de código, pero cambiando con tus credenciales que antes ya habíamos usado:
spark.master local[*, 4] spark.databricks.cluster.profile singleNode spark.mongodb.output.uri <CADENA DE CONEXIÓN PRICIPAL> spark.mongodb.input.uri <CADENA DE CONEXIÓN PRICIPAL>
Te quedará algo así

Finalmente creamos el Computo/Clúster, cuándo se cree correctamente vamos agregar las librerías necesarias.



Instalamos:

Entramos:

Comprobamos que se ha creado correctamente

Creamos un nuevo notebook y cargamos el contenido de nuestro notebook.

Notebook
Vamos a actualizar las configuraciones utilizando los datos de nuestra base de datos. Esto incluye cambiar la URI de nuestra conexión para que coincida con la que utilizamos previamente al ejecutar el script en Python. De esta forma, nos aseguramos de que nuestras credenciales y parámetros de conexión estén correctamente configurados y alineados con nuestra base de datos en Cosmos DB.

Luego de realizar la conexion, creamos un dataframe para manejar mejor los datos:

Y finalmente guardamos como una tabla.

PowerBI
Ahora que tenemos todo creado, vamos a realizar visualizaciones con PowerBI. Primero, dentro de Databricks, seguimos estos pasos:
- Acceder a la Sección de Catálogo en Databricks: Inicia sesión en tu instancia de Databricks y navega a la sección de Catálogo en el menú lateral.
- Verificar el hive_metastore: En la sección de Catálogo, verifica que se ha creado un
hive_metastore. Este metastore contiene todas las tablas que hemos creado durante el procesamiento de datos. - Confirmar la Tabla Creada: Dentro del
hive_metastore, localiza la tabla que creamos anteriormente en el notebook de Databricks. Esta tabla contiene los datos procesados y listos para la visualización.


Conectar PowerBI a Databricks a través de Partner Connect
Acceder a Partner Connect: En el portal de Databricks, en la barra lateral izquierda, desplázate hacia abajo hasta encontrar la opción Partner Connect. Haz clic para abrir la sección.
Seleccionar PowerBI: Dentro de Partner Connect, busca y selecciona la opción PowerBI. Esto iniciará el proceso de configuración para conectar Databricks con PowerBI.

Seleccionamos nuestro clúster y descargamos el archivo de conexion.

Te saldra un mensaje como este:

Asegúrate de tener instalada la versión de PowerBI que se indica en el mensaje. Una vez que PowerBI Desktop esté instalado, abre el archivo que descargaste previamente usando la aplicación de PowerBI o selecciona la opción para abrir el archivo desde tu dispositivo dentro de la aplicación.
Te pedirá que inicies sesión. Selecciona Azure Active Directory y utiliza el correo electrónico registrado en Azure para iniciar sesión. Luego, haz clic en Conectar.

Se mostrará el contenido de nuestro hive_metastore. Marca la casilla de la tabla powerbitable y haz clic en Cargar para importar los datos a PowerBI.


Ahora podemos crear algunas gráficas. Para empezar:
Seleccionar el Tipo de Gráfico: En PowerBI, selecciona el tipo de gráfico Mapa desde el panel de visualizaciones.
Asignar el Parámetro: En el panel de campos, marca el parámetro city y arrástralo al área de ubicación del gráfico de mapa.
Ver el Mapa Creado: Una vez asignado el parámetro city, PowerBI generará un mapa que mostrará las ubicaciones de las ciudades correspondientes a los datos climáticos que hemos importado

Crear Gráficos en PowerBI
Seleccionar Campos de Datos: Selecciona los campos de datos que deseas visualizar en PowerBI desde el panel de campos.
Elegir Tipo de Gráfico: Elige el tipo de gráfico que mejor represente los datos que quieres mostrar (por ejemplo, gráficos de líneas para la evolución del clima, gráficos de barras para comparaciones, etc.).
Personalizar Visualizaciones: Personaliza las visualizaciones ajustando colores, etiquetas, y estilos según tus preferencias y necesidades.
Crear Dashboard: Organiza tus visualizaciones en un dashboard para tener una vista completa y coherente de los datos climáticos.
Gráficas:
- Línea de tiempo de la temperatura:

- Línea de tiempo de presíon:

- Línea de tiempo de humedad:

- Velocidad del viento y clima: Examina si las velocidades más altas del viento están asociadas a eventos meteorológicos como tormentas o nubes densas.

- Distribución de temperaturas: Muestra la distribución de temperaturas para identificar rangos comunes o externos.

- Detección de anomalías: Identifica eventos donde las condiciones cambian abruptamente, como un descenso súbito de temperatura o cambios en la presión.

- Transiciones climáticas: Rastrea cómo un tipo de clima evoluciona con el tiempo

Las gráficas dependerán del enfoque que quieras darle y de la cantidad de datos disponibles.


Conclusión
Este proyecto de análisis del clima te brinda una experiencia completa y práctica en la recolección, almacenamiento, procesamiento y visualización de datos utilizando herramientas modernas y ampliamente utilizadas en la industria. Desde la configuración de recursos en Azure y la integración con la API de OpenWeather, hasta el procesamiento de datos en Databricks y la creación de visualizaciones impactantes en PowerBI, has adquirido habilidades valiosas y conocimientos profundos que son esenciales para cualquier analista de datos. Este proyecto no solo te ayuda a entender los conceptos clave de análisis de datos, sino que también te prepara para enfrentar desafíos reales y trabajar con tecnologías de vanguardia en tu futura carrera profesional.