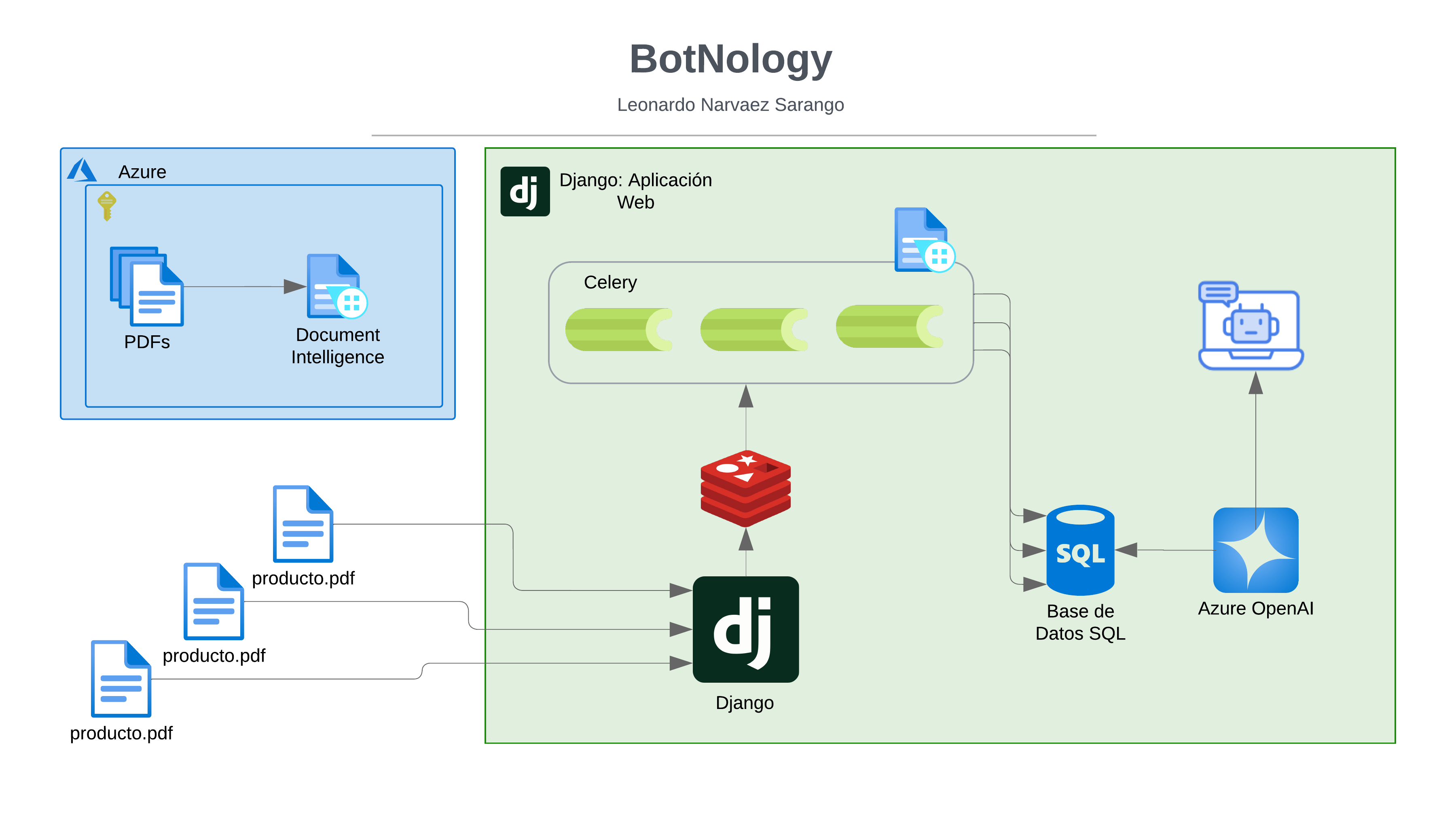
Introducción:
En este tutorial, aprenderás cómo instalar y configurar Databricks, una plataforma basada en la nube que permite trabajar de manera eficiente con grandes volúmenes de datos y facilitar tareas de Machine Learning. Aunque Databricks es mayormente conocido por ser una plataforma optimizada para Apache Spark, también ofrece potentes herramientas para el análisis de datos, la colaboración y la ejecución de modelos ML.
A continuación, te mostraré cómo configurar Databricks paso a paso para que puedas comenzar a aprovechar al máximo esta plataforma.
Paso 1: Crear una Cuenta en Databricks
Lo primero que necesitas hacer es crear una cuenta en Databricks. Si ya tienes una cuenta, puedes saltar al siguiente paso.
- Ir a la página oficial de Databricks:
- Accede a Databricks.
- Registrarse para obtener una cuenta gratuita:
- Haz clic en "Get Started Free" (Comenzar Gratis). Esto te llevará a una página donde puedes registrarte utilizando tu correo electrónico, o bien, puedes hacerlo a través de tu cuenta de Google, Microsoft o GitHub.
- Completa el formulario:
- Completa los detalles necesarios, como nombre, correo electrónico y la empresa o institución (puedes poner algo general si no trabajas para una empresa específica).
- Verifica tu correo:
- Si te piden verificar tu dirección de correo electrónico, revisa tu bandeja de entrada y haz clic en el enlace de verificación.
Paso 2: Crear un Clúster en Databricks
Una vez que te hayas registrado y accedido a tu cuenta, el siguiente paso es crear un clúster. Los clústeres son grupos de máquinas virtuales que Databricks utiliza para ejecutar tareas de procesamiento de datos.
- Iniciar sesión en Databricks:
- Accede con tu cuenta de usuario.
- Ir al menú de Clústeres:
- En la barra lateral izquierda, selecciona "Clusters".

- Crear un nuevo clúster:
- Haz clic en "Create Cluster". Aparecerá un formulario donde tendrás que configurar algunos parámetros para tu clúster.
Configurar los parámetros del clúster:
- Cluster Name: Asigna un nombre a tu clúster.
- Cluster Mode: Selecciona Standard si es para un uso general o High Concurrency para ejecutar múltiples trabajos simultáneamente.
- Databricks Runtime Version: Elige la versión recomendada o la que mejor se adapte a tus necesidades. Generalmente, se recomienda la última versión estable, en esta clase dejaremos la versión de Spark.

- Lanzar el clúster:
- Haz clic en Create Cluster para iniciar la configuración. Una vez creado, tu clúster comenzará a arrancar.
Paso 3: Importar Datos y Crear Tablas en Databricks
En Databricks, puedes importar datos de manera sencilla desde diferentes fuentes. En este tutorial, vamos a trabajar con archivos CSV ubicados en un directorio /sample_data. A continuación, te guiaré por el proceso de cargar esos archivos y crear las tablas correspondientes en un notebook de Databricks.
Subir Datos a Databricks
- Seleccionar "Create Table": En el apartado de inicio de Databricks, selecciona la opción "Create Table" que aparece en la interfaz de usuario.

Seleccionar la ubicación de los archivos:
- A continuación, selecciona "Upload Data" y elige la opción para cargar los archivos desde tu máquina o desde una ubicación de almacenamiento en la nube como DBFS (Databricks File System).
- En este caso, los archivos CSV estarán ubicados en la carpeta
/sample_data, que se encuentra dentro de tu espacio de trabajo en Databricks.

Adjuntar los archivos CSV:
- Selecciona los archivos CSV que deseas cargar desde la carpeta
/sample_data. Puedes seleccionar varios archivos que te dejare disponibles en el repositorio. - Una vez cargados, Databricks te pedirá que crees una tabla a partir de estos archivos. Haz clic en la opción "Create Table in Notebook" para continuar

Este paso llevará a la pestaña de edición del Notebook, donde puedes realizar el procesamiento de los datos y crear las tablas necesarias para tus análisis.
Paso 4: Importar un Notebook para Procesamiento de Datos
Una vez que los datos están cargados y las tablas creadas, puedes importar un notebook desde un repositorio externo (por ejemplo, GitHub) para realizar un procesamiento más avanzado de los datos.
Descargar el Notebook desde GitHub
- Databricks genera un notebook por defecto que puede dar fallos, dejare un notebook listo en el repositorio de GitHub.
- Dentro de Databricks, selecciona File > Import > Import From File.

- En el cuadro de diálogo que aparece, selecciona el archivo del notebook descargado desde GitHub y adjúntalo en Databricks.

Ejecutar el Notebook
- Una vez importado el notebook, se abrirá automáticamente en la interfaz de Databricks.
- Seleccionar el Clúster: En la parte superior del notebook, junto al botón Share y Publish, asegúrate de seleccionar el clúster que creaste previamente. Esto es esencial para que el notebook se ejecute correctamente sobre los recursos del clúster que configuraste en el paso anterior.

- Ejecutar el Notebook: Ahora, para ejecutar todo el código de manera secuencial, haz clic en el botón "Run All". Esto ejecutará todas las celdas del notebook, realizando las transformaciones necesarias y creando las vistas y tablas a partir de los archivos CSV cargados anteriormente.

- Si quieres publicar y tener acceso desde fuera a este notebook puedes "Publish" el notebook.


- Una vez publicado el notebook, se crea un enlace donde puedes acceder directamente desde el enlace a tu notebook.


Paso 5: Visualizar los Resultados y Consultas
Una vez que el notebook se haya ejecutado, se habrán creado las tablas en tu base de datos, y podrás visualizar los resultados de las consultas que se han realizado.

Consultas Básicas
En el notebook, se pueden personalizar las consultas SQL para obtener la información que necesitas. Por ejemplo, si estás trabajando con datos sobre ardillas (sólo como ejemplo), puedes ejecutar una consulta para ver cuántas ardillas han sido observadas en el conjunto de datos.
Aquí tienes un ejemplo de una consulta básica:
SELECT * FROM squirrels
Visualización de Resultados
Databricks también te permite visualizar los resultados de las consultas directamente en el notebook. Después de ejecutar una consulta, verás los resultados en una tabla interactiva. Puedes incluso crear gráficos a partir de estos resultados utilizando las herramientas integradas de visualización de Databricks.
Paso 6: Personalización y Optimización de Consultas
Aunque el notebook predeterminado generará algunas consultas básicas, puedes personalizarlas según tus necesidades. Si deseas realizar análisis más complejos, puedes modificar las consultas, agregar nuevas transformaciones o incluso combinar diferentes fuentes de datos.
Recuerda que Databricks es muy flexible y permite ejecutar tanto código SQL como PySpark, lo que te da mucha libertad para manipular y analizar tus datos.
1. Personalizar Consultas
En el notebook, puedes personalizar las consultas para obtener los resultados que necesitas. Por ejemplo, si deseas filtrar registros con valores nulos en alguna columna o realizar un análisis más detallado de los datos, puedes escribir una consulta SQL avanzada.
Aquí tienes un ejemplo de una consulta SQL para seleccionar las columnas Squirrel_ID y Other_Notes de la tabla squirrels, pero solo aquellas filas donde la columna Other_Notes no sea nula:
SELECT Squirrel_ID, Other_Notes FROM hive_metastore.default.squirrels WHERE Other_Notes IS NOT NULL;
Esta consulta te permitirá filtrar solo aquellos registros en los que haya información en la columna Other_Notes, lo que puede ser útil si estás interesado solo en las observaciones completas o específicas.

Conclusión
Con estos pasos, has aprendido cómo importar datos a Databricks, ejecutar un notebook para procesarlos y visualizar los resultados. Además, ahora sabes cómo personalizar las consultas dentro del notebook para hacer análisis más detallados. Databricks es una plataforma extremadamente poderosa que te permitirá aprovechar al máximo el procesamiento de grandes volúmenes de datos.