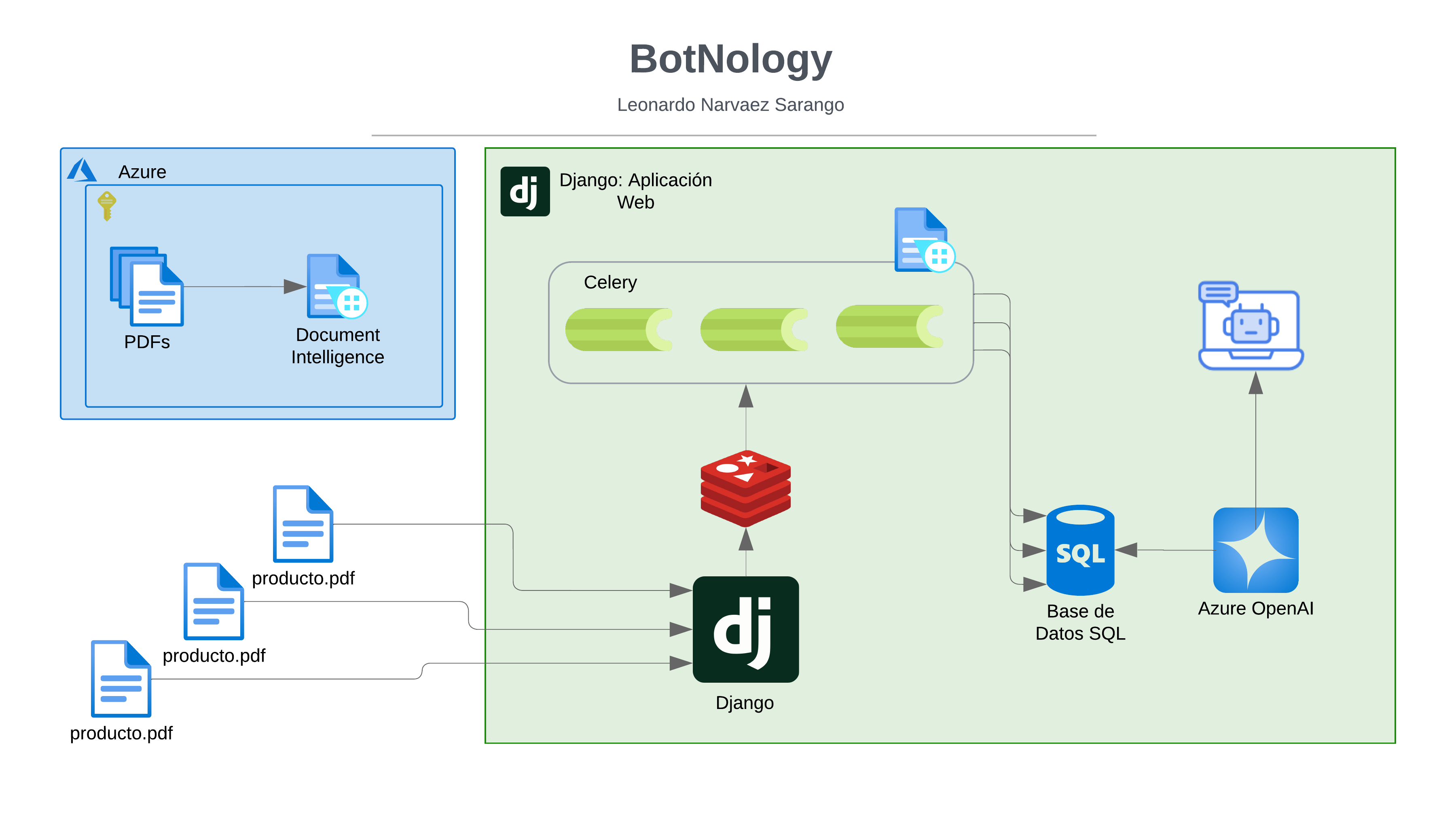
Introducción:
En este tutorial, aprenderás cómo transformar un conjunto de datos de retrasos en vuelos utilizando Python y las herramientas disponibles en Kaggle. A lo largo del ejercicio, te guiaré paso a paso para que puedas filtrar la información clave del dataset, como la fecha del vuelo, la aerolínea y el retraso de salida. Además, exploraremos cómo guardar estos datos en diferentes formatos de almacenamiento eficientes, como Parquet, ORC, y Avro, que son ampliamente utilizados para el procesamiento y análisis de grandes volúmenes de datos.
Te mostraré cómo utilizar bibliotecas como Pandas, PyArrow y Fastavro para manejar y optimizar los datos, así como cómo aplicar compresión en los formatos ORC para mejorar la eficiencia del almacenamiento. Al final de este tutorial, tendrás una comprensión sólida sobre cómo transformar, persistir y optimizar datos en distintos formatos, lo cual es fundamental en proyectos de análisis de datos a gran escala. ¡Empecemos!
Requisitos Previos
Antes de comenzar con este ejercicio en Kaggle, asegúrate de cumplir con los siguientes requisitos:
1. Crear una Cuenta en Kaggle
Si aún no tienes una cuenta en Kaggle, necesitas crear una. Kaggle es una plataforma en línea que permite a los usuarios acceder a datasets, competir en desafíos de ciencia de datos y trabajar en proyectos de análisis de datos con notebooks interactivos.
- Ve a la página de Kaggle y regístrate si no tienes una cuenta.
- Si ya tienes cuenta, simplemente inicia sesión.
2. Acceder a Kaggle Notebooks
Kaggle ofrece un entorno de notebooks en la nube para que puedas trabajar directamente con Python y otros lenguajes sin necesidad de configurar tu entorno local. Para acceder a los notebooks:
- Inicia sesión en Kaggle.
- Dirígete a la sección de Notebooks.
- Haz clic en "New Notebook" para crear un nuevo proyecto.
3. Subir el Dataset de Retrasos en Vuelos (si es necesario)
Si no estás trabajando con un dataset predefinido en Kaggle, necesitarás cargar el archivo CSV con los datos de retrasos en vuelos. Para ello:
- Haz clic en el icono de "Data" en la barra lateral izquierda de tu notebook.
- Selecciona "Add Dataset" y busca el dataset que deseas utilizar (puedes buscar un dataset de vuelos retrasados en Kaggle). Dataset.

- Si tienes el archivo CSV en tu computadora, puedes subirlo directamente haciendo clic en "Upload".
Cargar el Dataset (CSV 2018)
Como ya tienes el archivo CSV con los datos de retrasos en los vuelos en tu entorno de Kaggle, el primer paso es cargarlo en un DataFrame de Pandas.
import pandas as pd
# Cargar el archivo CSV de retrasos en los vuelos de 2018
df = pd.read_csv('/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2018.csv')
# Ver las primeras filas para asegurarnos de que el archivo se cargó correctamente
df.head()

Asegúrate de reemplazar '/kaggle/input/airline-delays-and-cancellation-data-2009-2018/2018.csv' con la ruta correcta si el archivo tiene otro nombre o está en otra carpeta dentro de los archivos de entrada. Podemos verlo en nuestro notebook en la parte de Inputs.
Convertir el DataFrame a formato Parquet
Ahora podemos usar la librería pyarrow para convertir el DataFrame a formato Parquet.
import pandas as pd
# Guardar el DataFrame completo en formato Parquet en el directorio de salida de Kaggle
df.to_parquet('/kaggle/working/air2018.parquet')
print("Archivo Parquet guardado exitosamente.")
Para comprobar que se ha guardado correctamente filtramos las primeras filas de nuestro dataset.
# Leer el archivo Parquet guardado
df_parquet = pd.read_parquet('/kaggle/working/air2018.parquet')
# Verificar las primeras filas del archivo Parquet
df_parquet.head()

Convertir el Dataset a formato Orc
Luego, con PyArrow, podemos convertir el DataFrame de Pandas a una tabla de PyArrow y guardarla en formato ORC.
import pyarrow as pa
import pyarrow.orc as orc
# Convertir el DataFrame de Pandas a una tabla de PyArrow
table = pa.Table.from_pandas(df)
# Guardar la tabla en formato ORC en el directorio de salida de Kaggle
table.to_pandas().to_orc('/kaggle/working/air2018.orc')
print("Archivo ORC guardado exitosamente.")
Como siempre, puedes cargar y verificar que el archivo ORC se haya guardado correctamente:
import pyarrow.orc as orc
# Leer el archivo ORC guardado
table_orc = orc.read_table('/kaggle/working/air2018.orc')
# Convertir a pandas para inspeccionar las primeras filas
df_orc = table_orc.to_pandas()
df_orc.head()

Guardar en formato ORC con compresión Snappy
Para esto, vamos a usar PyArrow para aplicar compresión Snappy al archivo ORC.
import pyarrow as pa import pyarrow.orc as orc
# Convertir el DataFrame de Pandas a una tabla de PyArrow
table = pa.Table.from_pandas(df)
# Guardar la tabla en formato ORC con compresión Snappy en el directorio de salida de Kaggle
orc.write_table(table, '/kaggle/working/air2018_snappy.orc', compression='SNAPPY')
print("Archivo ORC con compresión Snappy guardado exitosamente.")
Para verificar que el archivo ORC comprimido con Snappy se guardó correctamente, puedes leer el archivo y mostrar las primeras filas:
# Leer el archivo ORC comprimido con Snappy
table_orc_snappy = orc.read_table('/kaggle/working/air2018_snappy.orc')
# Convertir a pandas para inspeccionar las primeras filas
df_orc_snappy = table_orc_snappy.to_pandas()
df_orc_snappy.head()

Convertir Dataset filtrado a Avro
Ahora vamos hacer un filtrado previo para hacer un Dataset pequeño.
import pandas as pd
import fastavro
# Seleccionar las columnas necesarias
df_small = df[['FL_DATE', 'OP_CARRIER', 'DEP_DELAY']]
# Definir el esquema de Avro
schema = {
"type": "record",
"name": "FlightRecord",
"fields": [
{"name": "FL_DATE", "type": "string"},
{"name": "OP_CARRIER", "type": "string"},
{"name": "DEP_DELAY", "type": ["null", "float"], "default": None},
]
}
# Convertir el DataFrame a una lista de diccionarios
records = df_small.to_dict(orient='records')
# Guardar los datos como archivo Avro
with open('/kaggle/working/air2018_small.avro', 'wb') as out:
fastavro.writer(out, schema, records)
print("Archivo Avro guardado exitosamente.")
Si quieres leer el archivo Avro para ve que se guardo correctamente:
# Leer el archivo Avro guardado
import fastavro
with open('/kaggle/working/air2018_small.avro', 'rb') as f:
reader = fastavro.reader(f)
# Convertimos a pandas para poder visualizarlo
df_avro = pd.DataFrame(reader)
# Verificar las primeras filas
df_avro.head()

Convertir DataSet Filtrado en formato Parquet
import pandas as pd
# Seleccionar las columnas necesarias
df_small = df[['FL_DATE', 'OP_CARRIER', 'DEP_DELAY']]
# Guardar el DataFrame en formato Parquet
df_small.to_parquet('/kaggle/working/air2018_small.parquet', engine='pyarrow')
print("Archivo Parquet guardado exitosamente.")
Mostramos el contenido para ver si se guardo correctamente.
# Leer el archivo Parquet guardado
df_parquet = pd.read_parquet('/kaggle/working/air2018_small.parquet', engine='pyarrow')
# Verificar las primeras filas
df_parquet.head()

Al finalizar la practica te debe quedar los siguientes archivos dentro del output:

Comprobación:
Después de crear todos los archivos vamos a crear una función para poder comparar el tamaño y el tiempo que tarda en crearse.
import os
import time
import pandas as pd
import pyarrow.parquet as pq
import pyarrow.orc as orc
import pyarrow as pa
import fastavro
# Crear una función para medir el tiempo de creación de cada archivo
def measure_time(func, *args):
start_time = time.time() # Iniciar el cronómetro con mayor precisión
func(*args) # Ejecutar la función para crear el archivo
end_time = time.time() # Finalizar el cronómetro
return round((end_time - start_time)* 1000, 2) # Retornar el tiempo transcurrido
# Lista de archivos a generar (ahora con el archivo 'air2018_small.parquet' incluido)
output_files = [
"air2018.parquet",
"air2018.orc",
"air2018_snappy.orc",
"air2018_small.avro",
"air2018_small.parquet"
]
# Lista para almacenar los resultados
results = []
# 1. Crear archivo Parquet
def create_parquet(df, filename):
df.to_parquet(filename)
parquet_time = measure_time(create_parquet, df, output_files[0])
# 2. Crear archivo ORC
def create_orc(df, filename):
table = pa.Table.from_pandas(df)
with open(filename, 'wb') as f:
orc.write_table(table, f)
orc_time = measure_time(create_orc, df, output_files[1])
# 3. Crear archivo ORC con compresión Snappy
def create_orc_snappy(df, filename):
table = pa.Table.from_pandas(df)
with open(filename, 'wb') as f:
orc.write_table(table, f, compression='SNAPPY')
orc_snappy_time = measure_time(create_orc_snappy, df, output_files[2])
# 4. Crear archivo Avro
def create_avro(df, filename):
records = df.to_dict(orient='records')
schema = {
'type': 'record',
'name': 'flight',
'fields': [
{'name': 'FL_DATE', 'type': 'string'},
{'name': 'OP_CARRIER', 'type': 'string'},
{'name': 'DEP_DELAY', 'type': 'int'}
]
}
with open(filename, 'wb') as out:
writer = fastavro.writer(out, schema, records)
avro_time = measure_time(create_avro, df, output_files[3])
# 5. Crear archivo Parquet pequeño (solo con las columnas necesarias)
def create_small_parquet(df, filename):
df_small = df[['FL_DATE', 'OP_CARRIER', 'DEP_DELAY']] # Selección de columnas
df_small.to_parquet(filename)
small_parquet_time = measure_time(create_small_parquet, df, output_files[4])
# Almacenar los resultados (archivo, tamaño y tiempo de creación)
for i, file in enumerate(output_files):
file_size = os.path.getsize(file)
# Usar el tiempo correspondiente basado en el índice de la lista
times = [parquet_time, orc_time, orc_snappy_time, avro_time, small_parquet_time]
results.append({
"Archivo": file.split('/')[-1], # Para mostrar solo el nombre del archivo sin la ruta
"Tamaño": round(file_size, 2),
"Tiempo de creación (milisegundos)": times[i]
})
# Crear un DataFrame con los resultados
df_results = pd.DataFrame(results)
# Mostrar la tabla de resultados
df_results

Conclusión
En este ejercicio hemos generado y comparado varios formatos de almacenamiento para los datos de retrasos de vuelos de 2018. Los formatos utilizados son Parquet, ORC, Snappy-ORC, y Avro, y hemos analizado dos aspectos clave para la optimización del almacenamiento y rendimiento de los datos:
- Tamaño de los archivos: Se observó una notable diferencia en el tamaño de los archivos generados en cada formato. El formato ORC y Snappy-ORC resultaron ser más eficientes en términos de compresión, especialmente al utilizar Snappy en ORC, que puede ser más adecuado cuando se necesita un balance entre tamaño y velocidad de lectura/escritura.
- Tiempo de creación: El tiempo de creación varió entre los diferentes formatos. Aunque no hubo grandes diferencias, Avro fue el formato que tomó más tiempo en procesar, posiblemente debido a la sobrecarga de la serialización de datos complejos. En cambio, Parquet y ORC mostraron tiempos de creación relativamente rápidos, lo que hace que estos formatos sean adecuados para grandes volúmenes de datos.
Resumen de los resultados:
- Parquet y Snappy-ORC son muy eficientes en términos de tamaño, lo que los convierte en una excelente opción cuando se trabaja con grandes volúmenes de datos y se busca minimizar el espacio de almacenamiento.
- Avro es más pesado en tamaño y requiere un poco más de tiempo para crear los archivos, pero sigue siendo un formato útil cuando la interoperabilidad entre diferentes sistemas es un factor importante.
- En términos de tiempo de creación, los formatos ORC y Snappy-ORC son los más rápidos, lo que hace que sean ideales para procesamiento en tiempo real o con grandes flujos de datos.
Lecciones aprendidas:
Este ejercicio refuerza la importancia de elegir el formato adecuado para almacenar datos en función de las necesidades específicas del proyecto. Mientras que Parquet y ORC son excelentes opciones para almacenamiento eficiente y velocidad, Avro puede ser útil en escenarios donde la interoperabilidad entre sistemas es crucial. Además, la compresión mediante Snappy puede ser una opción a considerar cuando se busca reducir el tamaño de los archivos sin sacrificar demasiado el rendimiento.
En resumen, este análisis nos ayuda a entender cómo balancear tamaño, rendimiento y flexibilidad en el almacenamiento de datos, lo cual es esencial para gestionar grandes volúmenes de información en el mundo real.