Introducción:
En el mundo actual de los datos, las empresas están generando grandes volúmenes de información que necesitan ser procesados, analizados y almacenados de manera eficiente. Para abordar estos desafíos, Azure HDInsight ofrece una solución robusta y completamente administrada que facilita el procesamiento de macrodatos utilizando tecnologías de código abierto como Apache Hadoop y Apache Hive. En este tutorial, aprenderás cómo crear y gestionar clústeres de Hadoop en HDInsight a través de Azure Portal, ejecutar trabajos de Apache Hive para realizar consultas de datos y, finalmente, limpiar los recursos una vez que hayas terminado.
Creación de un clúster de Apache Hadoop
En esta sección, aprenderás cómo crear un clúster de Hadoop en Azure HDInsight utilizando el Azure Portal. Sigue estos pasos para configurar y lanzar tu clúster:
- Inicia sesión en Azure Portal:
- Accede a tu cuenta en Azure Portal.
- En el menú superior, selecciona + Crear un recurso.

Configuración del Grupo de Recursos:
Un grupo de recursos en Azure es un contenedor que agrupa recursos relacionados que se administran como una única unidad. Los recursos dentro de un grupo de recursos comparten el mismo ciclo de vida, es decir, pueden ser creados, actualizados o eliminados de manera conjunta.
¿Para qué sirve un grupo de recursos?
- Organización: Facilita la organización y gestión de los recursos dentro de Azure, agrupando aquellos que son utilizados por una misma aplicación o proyecto.
- Gestión de permisos: Permite establecer permisos de acceso a los recursos dentro del grupo de manera centralizada.
- Gestión de costos: Facilita la asignación de costos y el seguimiento de los recursos asociados a un proyecto específico.
- Facilita la administración: Permite aplicar políticas y configuraciones de forma coherente a todos los recursos dentro del grupo.
- Busca o selecciona "Grupo de recursos" y configúralo de la siguiente manera:

- Damos clic en "Revisar y Crear" ya que no es necesario agregar nada más, si todo va bien se mostrará así:

- Da clic en "Crear".

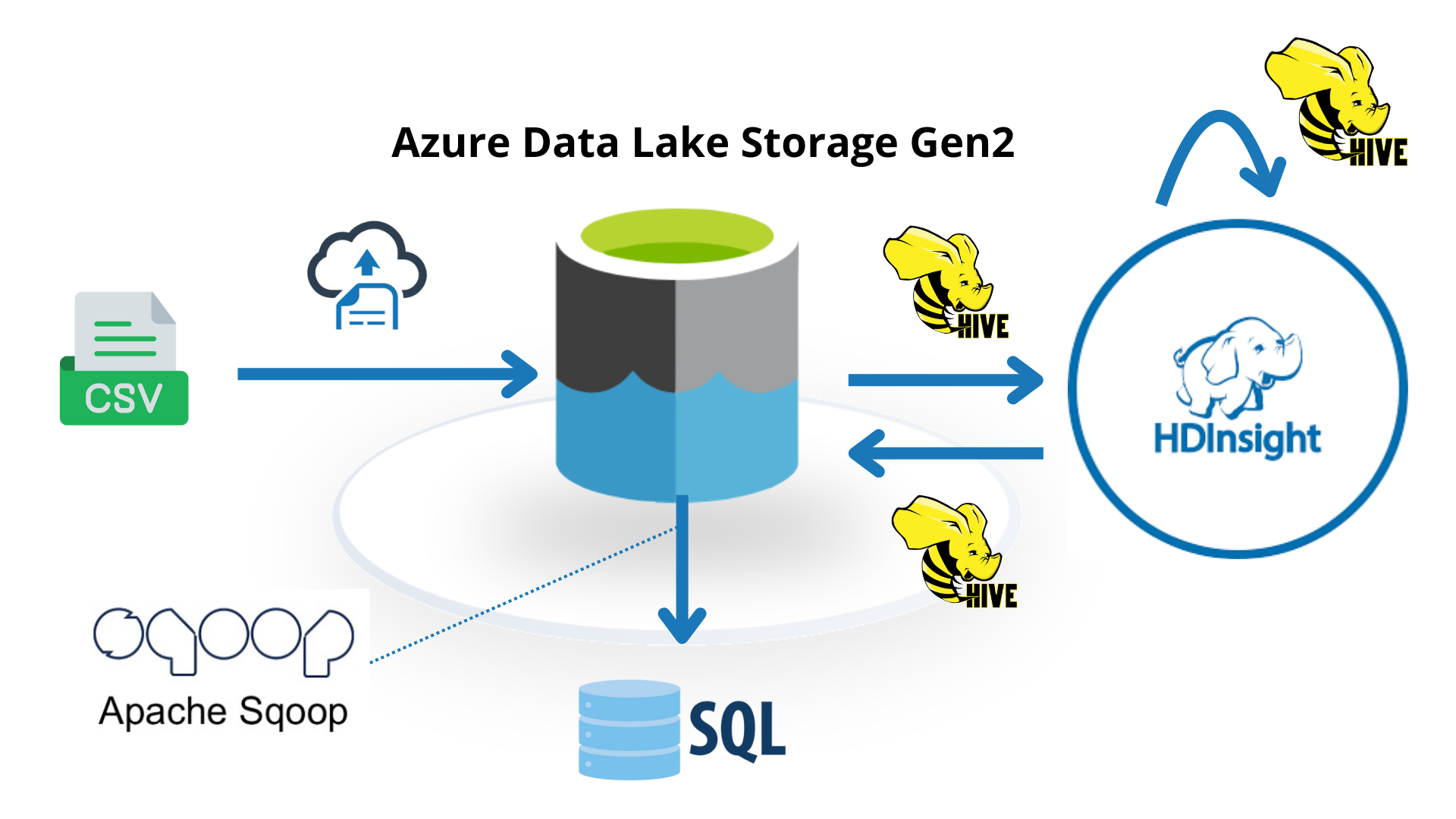
Crear Source: Azure Data Lake Storage Gen2:
Azure Data Lake Storage Gen2 es una solución de almacenamiento optimizada para grandes volúmenes de datos y análisis avanzados. Combina las capacidades de Azure Blob Storage con un sistema de archivos jerárquico, permitiendo almacenar, administrar y analizar datos a gran escala de forma eficiente. Al crear un "Source" en Azure Data Lake Storage Gen2, estableces una ubicación centralizada para almacenar y procesar grandes cantidades de datos no estructurados, ideales para análisis y machine learning.
Creación de Cuentas de Almacenamiento:
Las cuentas de almacenamiento en Azure se crean para proporcionar un espacio seguro y escalable donde almacenar y administrar diferentes tipos de datos. Estas cuentas permiten almacenar archivos, blobs, colas, tablas y discos virtuales, entre otros.
- Buscamos o seleccionamos "Cuentas de Almacenamiento".

Datos Básicos:

Avanzado:


Redes:


Protección de Datos:


Cifrado:

Etiquetas:
Las puedes dejar en blanco, no es necesario agregar ninguna etiqueta.
Crear:
Damos clic a "Revisar y Crear" y si todo va bien damos en "Crear"

Crear servicio de SQL Server:
SQL Server ofrece una versión gestionada en la nube a través de Azure SQL Database, permitiendo a las organizaciones operar bases de datos sin necesidad de gestionar el hardware o la infraestructura subyacente. Proporciona características avanzadas como alta disponibilidad, recuperación ante desastres, seguridad integrada y escalabilidad automática, facilitando la administración de bases de datos con un mínimo esfuerzo.
- Buscamos o seleccionamos "SQL Database".

- Damos clic en "Crear".
Creando un Servidor Database:
Ahora vamos a configurar SQL Database. Para eso primero tenemos que crear un "Servidor", así que antes de guardar las configuraciones nos deslizamos hasta Detalles de la base de datos > Servidor y da en Nuevo.

- Creamos el servidor con las siguientes configuraciones:

- En "Configurar administrar de Microsoft Entra", establecemos el administrador con nuestra cuenta Estudiantil:

Básico:


- Antes de avanzar en "Proceso y Almacenamiento" configuramos la base de la siguiente manera:


Redes:

Seguridad:


Configuraciones adicionales:

Etiquetas:
Las puedes dejar en blanco, no es necesario agregar ninguna etiqueta.
Crear:
Damos clic a "Revisar y Crear" y si todo va bien damos en "Crear"

Creando Consultas:
- Ahora vamos a "Ir al recurso" y damos clic en "Editor de consultas":

- Te saldrá un error con la autenticación
 Para solucionar el error sigue los siguientes pasos:
Para solucionar el error sigue los siguientes pasos:
- Vamos a "Incio"
- Buscamos o seleccionamos "Todos los recursos"
- Buscamos nuestro servidor "dbserver-practica09"
- Seleccionamos en la parte de Seguridad > Redes
- Marcamos en "Redes seleccionadas"
- Seleccionamos nuestra "Red de Firewall"
- Agregamos la dirección IPv4

- Al momento de agregar la dirección IP si da algún fallo, crea una nueva regla de firewall, guardando la direccion IP correspondiente, te debe quedar así:

- Guarda las configuraciones y vuelve a la base de datos en la sección de "Editor de consultas", el error se habrá solucionado.

- Ahora ya tendrás acceso al "Editor de consultas":

Añadiendo Managed Identity (Identidades Administradas):
El propósito de usar Managed Identity en Gen2 y en bases de datos es mejorar la seguridad y simplificar la gestión de credenciales. Managed Identity permite que los servicios de Azure se autentiquen de manera segura y sin necesidad de gestionar contraseñas o claves manualmente. Al habilitar esta identidad administrada, los recursos pueden interactuar entre sí de forma más segura y eficiente, cumpliendo con las políticas de acceso y control sin exponer credenciales.
- Busca o selecciona "Identidades Administradas"

- Da clic en "Crear"
- Guarda los datos de la siguiente manera:

- Da clic en "Revisar y crear", puedes dejar las etiquetas en blanco, no es necesario. Si todo esta correcto da clic en "Crear"

Asignar Identidades a Cuenta de Almacenaminto:
- Una vez creado, vamos al Inicio y buscamos nuestra Cuenta de almacenamiento "genstoragepractica"

- En la sección de Control de Acceso (IAM) y luego "Agregar asignación de roles"

Rol:
- Buscamos dentro a "Propietario de datos de Storage Blob" o "Storage Blob Data Owner", seleccionamos y damos a "Siguiente"

Miembros:
- Marcamos en "Identidad Administrada" y luego en agregar miembros, se abre un panel lateral donde seleccionas la identidad que creamos anteriormente, marcamos y damos en "Seleccionar"

- La configuración quedará de la siguiente manera:

Condición:
Dejamos la configuración por defecto
Asignar:
Damos clic a "Revisar y Asignar" y si todo va bien damos en "Asignar"
Asignar Identidades a SQL Server:
- Damos clic en Inicio y buscamos nuestro SQL Server "dbserver-practica09"

- En la sección de Control de Acceso (IAM) y luego "Agregar asignación de roles"

Rol:
- Buscamos "Colaborador de SQL Server" o "SQL Server Contributor", marcamos y damos en "Siguiente"

Miembros:
- Marcamos en "Identidad Administrada" y luego en agregar miembros, se abre un panel lateral donde seleccionas la identidad que creamos anteriormente, marcamos y damos en "Seleccionar"

- La configuración te quedará de la siguiente manera:

Asignar:
Damos clic a "Revisar y Asignar" y si todo va bien damos en "Asignar"
Asignar Identidades a HDInsight :
Asignar identidades a HDInsight permite una autenticación segura y sin necesidad de gestionar credenciales manualmente. Mediante el uso de Managed Identity, los clústeres de HDInsight pueden acceder a otros servicios de Azure de manera controlada y protegida, mejorando la seguridad y simplificando la administración de permisos.
- Vamos en inicio y buscamos "HDInsight Cluster"

- Damos clic en "Crear Clúster de HDInsight"
Datos Básicos:
- Definimos la siguiente configuración

- En la sección de "Tipo de Clúster" vamos a seleccionar "Interactive Query"

- Crear credenciales para el clúster:

Almacenamiento:

Seguridad y Redes:


Configuración y Precios:
- Cambiamos "Nodo Trabajador" de 4 a 1:

Etiquetas:
Podemos dejar por defecto, no hace falta agregar nada.
Crear:
Damos clic en "Revisar y Crear", si todo va bien damos clic en "Crear":

La implementación puede tardar varios minutos en crearse:

Data Ingestion: Data Lake Storage
Ahora vamos a cargar los datos dentro de nuestro Data Lake Storage
Vamos a cargar el archivo que tenemos disponible aquí.
Luego vamos a Azure a la sección de "genstoragepractica09":
- Dentro del recurso gestoragepractica09, vamos a la sección de "Explorador de Almacenamiento"
- Seleccionamos nuestro clúster:
- Luego en "Agregar directorio", creamos un directorio llamado "demo"

- Dentro del directorio "demo", crearemos otro directorio con el nombre "FlightDelayData", te quedará de la siguiente manera:

- Ahora vamos a cargar nuestros datos .csv, para ello, entramos al directorio "FlightDelayData", y en la parte superior damos clic en "Cargar", en el desplegable agregamos el archivo .csv y cargamos.

- Ya tendremos cargado nuestro archivo de datos dentro del Data Lake Storage:

Data Extraction: Hive
Ahora vamos a extraer los datos mediante la herramienta de Hive:
- Vamos al Inicio.
- Buscamos o seleccionamos nuestro clúster "cluster-pract09", dentro del recurso nos vamos a "Inicio de Ambari", te pedirá inicio de sesión, introduce tus credenciales y continua.

- Después de iniciar sesión correctamente, se cargara el dashboard así:

- Una vez dentro nos vamos a esta seccion para ingresar a Hive:

- Esperamos que cargue toda la configuración:

- Ahora ya podremos ver el dahsboard de queries de hive
- Vamos hacer algunas consultas para ver el contenido de nuestros datos del archivo .csv
- Dentro de la seccion de queries agrega los siguientes comandos:
DROP TABLE flightdelay_raw; CREATE EXTERNAL TABLE flightdelay_raw( YEAR string, FL_DATE string, UNIQUE_CARRIER string, CARRIER string, FL_NUM string, ORIGIN_AIRPORT_ID string, ORIGIN string, ORIGIN_CITY_NAME string, ORIGIN_CITY_NAME_TEMP string, ORIGIN_STATE_ABR string, DEST_AIRPORT_ID string, DEST string, DEST_CITY_NAME string, DEST_CITY_NAME_TEMP string, DEST_STATE_ABR string, DEP_DELAY_NEW float, ARR_DELAY_NEW float, CARRIER_DELAY float, WEATHER_DELAY float, NAS_DELAY float, SECURITY_DELAY float, LATE_AIRCRAFT_DELAY float) -- The following lines describe the format and location of the file ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION '/demo/FlightDelayData/InputData'; DROP TABLE flightdelay; CREATE TABLE flightdelay AS SELECT YEAR AS year, FL_DATE AS flight_date, substring(UNIQUE_CARRIER, 2, length(UNIQUE_CARRIER) -1) AS unique_carrier, substring(CARRIER, 2, length(CARRIER) -1) AS carrier, substring(FL_NUM, 2, length(FL_NUM) -1) AS flight_num, ORIGIN_AIRPORT_ID AS origin_airport_id, substring(ORIGIN, 2, length(ORIGIN) -1) AS origin_airport_code, substring(ORIGIN_CITY_NAME, 2) AS origin_city_name, substring(ORIGIN_STATE_ABR, 2, length(ORIGIN_STATE_ABR) -1) AS origin_state_abr, DEST_AIRPORT_ID AS dest_airport_id, substring(DEST, 2, length(DEST) -1) AS dest_airport_code, substring(DEST_CITY_NAME,2) AS dest_city_name, substring(DEST_STATE_ABR, 2, length(DEST_STATE_ABR) -1) AS dest_state_abr, DEP_DELAY_NEW AS dep_delay_new, ARR_DELAY_NEW AS arr_delay_new, CARRIER_DELAY AS carrier_delay, WEATHER_DELAY AS weather_delay, NAS_DELAY AS nas_delay, SECURITY_DELAY AS security_delay, LATE_AIRCRAFT_DELAY AS late_aircraft_delay FROM flightdelay_raw;
- Ejecuta la consulta:

- Si va todo bien, en la sección de "Tables", verás las tablas creadas con el script de SQL que ejecutamos anteriormente.

- Ahora para ver el contenido de las tablas ejecutaremos algunas consultas en la sección de "Query" agregamos un "Worksheet"
- Ejecutamos el siguiente comando para listar el contenido:
select * from flightdelay limit 5;

En esta sección hemos realizado la ingestión desde Data Lake Storage Gen 2 hasta un lugar dentro del clúster utilizando T-SQL mediante HIve.
Data Transformation: Hive
- Adicionamos un "Worksheet", agregamos y ejecutamos el siguiente comando:
INSERT OVERWRITE DIRECTORY '/demo/FlightDelayData/output' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT regexp_replace(origin_city_name, '''', ''), avg(weather_delay) FROM flightdelay WHERE weather_delay IS NOT NULL GROUP BY origin_city_name;
El comando INSERT OVERWRITE DIRECTORY escribe el resultado de una consulta en un archivo CSV en el directorio especificado de HDFS. En este caso, selecciona los nombres de las ciudades de origen de los vuelos (origin_city_name), eliminando las comillas simples, y calcula el promedio de los retrasos por condiciones climáticas (weather_delay) para cada ciudad, solo considerando aquellos registros donde el valor de weather_delay no es NULL. Los resultados se agrupan por ciudad de origen y se guardan en el directorio /demo/FlightDelayData/output en formato CSV, con los campos separados por comas.
Para ver lo que se ha generado:
- Dentro de Azure Portal, vamos al Inicio.
- Buscamos o seleccionamos nuestro gestor de almacenamiento: "genstoragepractica", entramos a "Contenedores" y seleccionamos nuestro contenedor del clúster.

- Dentro del Contenedor, abrimos la siguiente ruta dentro de los directorios demo>FlightDelayData>output y se verá la información creada, pero esta no tiene una estructura SQL, hive guardó la salida de chunks.

- Para sacar estos datos se puede recuperar usando la tecnología de SQOOP.
Data Export: Sqoop:
- Antes de usar sqoop vamos a nuestra base de datos desde Azure "dbpractica09" y en la seccion de "Editor de consultas", ejecutamos el siguiente comando:
CREATE TABLE [dbo].[delays]( [origin_city_name] [nvarchar](50) NOT NULL, [weather_delay] float, CONSTRAINT [PK_delays] PRIMARY KEY CLUSTERED ([origin_city_name] ASC)) GO SELECT * FROM information_schema.tables GO

Si todo va correctamente debe aparecer un mensaje que la consulta se ha realizado correctamente:

Regresamos a nuestro clúster para agregar la conexión SSH.
- Dentro del recurso vamos a la seccion de "Configuración" y luego a SSH e inicio de sesión del clúster, en nombre de host seleccionamos nuestro cluster.

- Copiamos la url para la conexión ssh que en nuestro caso es: "ssh sshuser@cluster-pract09-ssh.azurehdinsight.net".
- Abrimos la terminal integrada en Azure:

- Pegamos la url ssh que copiamos anteriormente, damos en "yes", finalmente introducimos la contraseña del admin:

Ahora usar sqoop primero instalaremos todo lo necesario
- Actualiza e instala dependencias:
sudo apt-get update sudo apt-get install openjdk-8-jdk wget ssh
- Instalamos Hadoop
sudo apt-get install hadoop
- Descargamos Sqoop
wget https://downloads.apache.org/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz tar -xvzf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz sudo mv sqoop-1.4.7.bin__hadoop-2.6.0 /opt/sqoop
Una vez que tenemos instalado sqoop:
----Continuará---