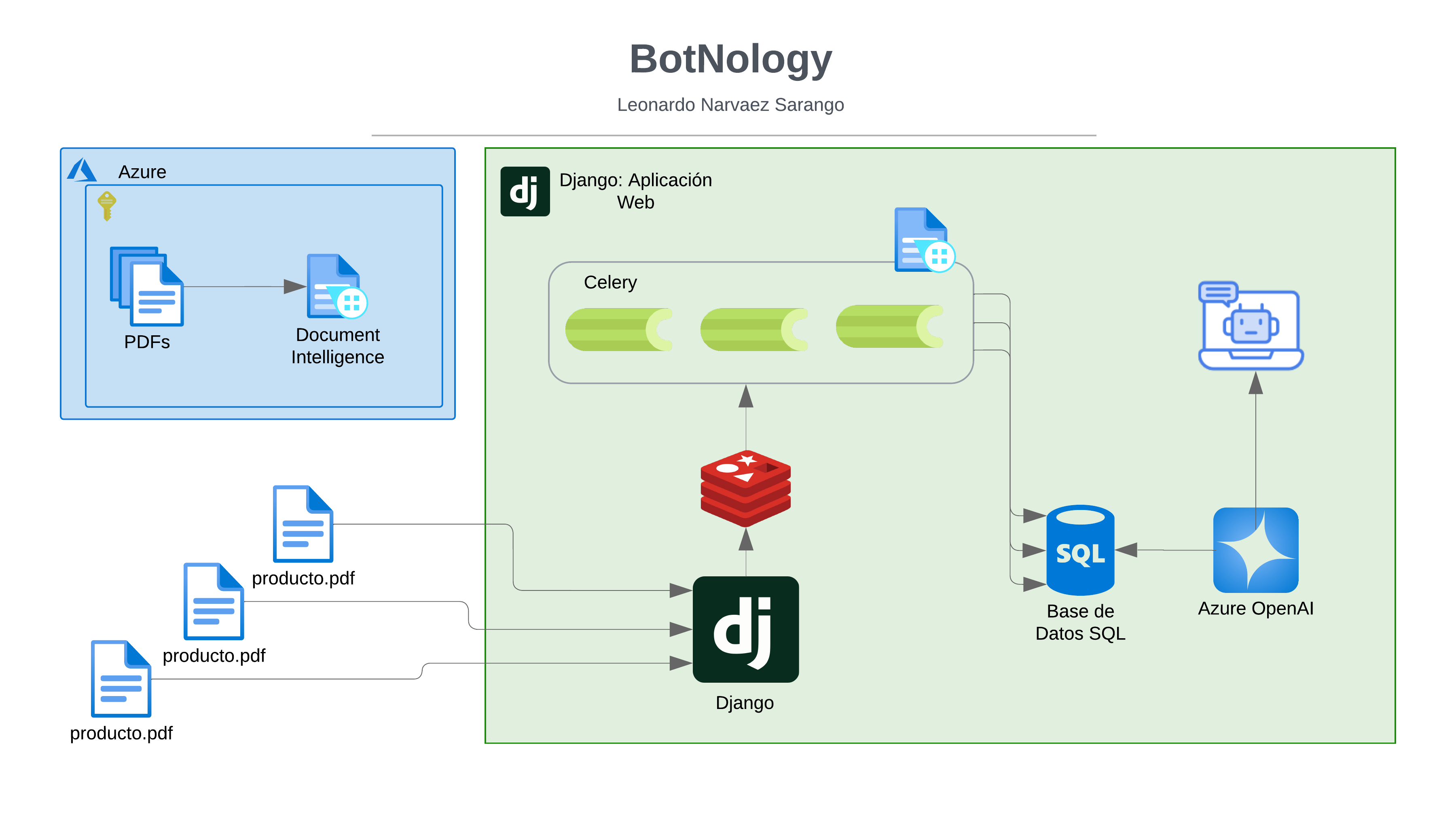
Introducción
Apache Hadoop es un marco de trabajo de código abierto que permite el procesamiento distribuido de grandes volúmenes de datos a través de clústeres de servidores. Con su capacidad para manejar grandes cantidades de información de manera eficiente, Hadoop se ha convertido en una herramienta fundamental para la gestión y el análisis de Big Data.
En esta guía, aprenderás a configurar un clúster multinodo de Hadoop sobre Ubuntu Server, lo que te permitirá experimentar con las principales características de Hadoop en un entorno real. El clúster multinodo es una arquitectura en la que varios nodos trabajan de manera conjunta para procesar datos, ofreciendo mayor capacidad de almacenamiento y rendimiento.
El objetivo de esta práctica es que comprendas el proceso de instalación, configuración y puesta en marcha de un clúster Hadoop, con el fin de familiarizarte con los componentes esenciales como el NameNode, DataNode, ResourceManager y NodeManager.
- NameNode: Es el nodo principal en el clúster de Hadoop. Su función principal es gestionar el sistema de archivos distribuido (HDFS) y almacenar la información sobre la estructura de los archivos, como los bloques y qué nodos los contienen. Es el "maestro" que coordina cómo se almacenan los datos y su acceso.
- DataNode: Son los nodos de almacenamiento en el clúster. Su función es almacenar realmente los bloques de datos y responder a las solicitudes del NameNode sobre el estado y ubicación de los bloques. Cada DataNode administra los datos locales y asegura que estén disponibles para su lectura o escritura.
- ResourceManager: Es el componente encargado de gestionar los recursos del clúster y coordinar las tareas de procesamiento. En un entorno YARN (Yet Another Resource Negotiator), el ResourceManager asigna recursos a las aplicaciones que se ejecutan en el clúster, como MapReduce, y supervisa su ejecución.
- NodeManager: Es el agente que corre en cada nodo del clúster (excepto en el que está el ResourceManager). Su tarea es gestionar los recursos locales del nodo (CPU, memoria, etc.), y reportar su disponibilidad al ResourceManager. También es responsable de ejecutar las aplicaciones asignadas a su nodo y monitorear su estado.
Configuración de Clúster Hadoop Multinodo
Para esta práctica, utilizaremos máquinas virtuales para simular un clúster de Hadoop multinodo. Para gestionar estas máquinas virtuales, necesitaremos una herramienta de virtualización. En este caso, VirtualBox es una excelente opción, ya que permite crear y gestionar múltiples máquinas virtuales de manera sencilla.
Puedes optar por cualquier otra herramienta de virtualización con la que te sientas cómodo, como VMware o KVM, pero VirtualBox es ampliamente utilizado y cuenta con una interfaz amigable y documentación detallada.
Configuración inicial de la Máquina Virtual:
Instala Virtualbox en tu sistema
Descarga la imagen de Ubuntu Server, la puedes encontrar aquí: UbuntuServer.
En Virtual Box crea la una "Nueva VM":
- Procesadores: 1
- RAM: 2080MB
- Red: NAT
Crea un nuevo usuario con privilegios de administrador.
- Utiliza el siguiente comando
sudo adduser hduser
- Agrega al nuevo usuario al grupo
sudo
sudo usermod -aG sudo hduser
- Una vez creado y configurado el nuevo usuario, cierra sesión del usuario actual.
exit
Inicia sesión en tu maquina virtual con el nuevo usuario "hduser", descarga e instala los programas necesarios.
# 1. Actualizar los paquetes del sistema
sudo apt update
# 2. Instalar las dependencias necesarias
sudo apt install vim ssh net-tools openjdk-11-jdk git
# 3. Cambiar al directorio home
cd ~
# 4. Descargar Hadoop desde el archivo oficial
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
# 5. Descomprimir el archivo descargado
tar xvf hadoop-3.3.2.tar.gz
# 6. Apagar la máquina
init 0
Configuraciones de red:
Ahora vamos habilitar la red "Host-only" en Virtuabox, para eso
- Abre VirtualBox y ve Archivo > Herramientas > Administrador de red. (Host Network Manager).
- Haz clic en Crear para crear una nueva red de solo host.

- Selecciona vboxnet0 y habilita el servidor DHCP para que asigne automáticamente una dirección IP a tus maquinas virtuales.

Ahora configuraremos la red de la maquina virtual
- Selecciona la maquina virtual (VM) en VirtualBox y haz clic en configuración.
- Ve a la sección de Red y habilita un adaptador adicionar (Adaptador 2)
- Configura este adaptador como Adaptador solo-anfitrión (Host-only Adapter) y selecciona vboxnet0 como la red. Haz clic en Aceptar para guardar los cambios.

Enciende tu maquina virtual e inicia sesión con "hduser".
- Verifica las interfaces de red actuales con el contenedor
sudo ip a
- Edita la configuración de red para asignar una dirección IP estática. Abre el archivo de configuración de netplan:
sudo vim /etc/netplan/01-netcfg.yaml
- Modifica el archivo de configuración de red para definir la IP estática en la interfaz enp0s8. La configuración te debe quedar de la siguiente manera:
network:
version: 2
renderer: networkd
ethernets:
enp0s3:
dhcp4: true
enp0s8:
addresses: [192.168.204.50/24]
dhcp4: false
Asegúrate que la dirección IP sea la misma que la del nuevo adaptador de red que hemos creado en los pasos anteriores.
- Después de editar el archivo, aplica la nueva configuración de red con:
sudo netplan apply
- Verifica que la IP estática se haya asignado correctamente, con el siguiente comando:
sudo ip a
Luego, necesitarás asegurarte de que los otros nodos puedan resolver los nombres de host de tus máquinas.
- Abre el archivo
/etc/hostsy agrega las IPs estáticas de tus nodos:
sudo vim /etc/hosts
- El archivo
/etc/hostsdebe verse así (ajustando las IPs según tu configuración):
192.168.204.50 master
192.168.204.51 worker1
192.168.204.52 worker2
192.168.204.53 worker3
Esto garantiza que cada nodo pueda resolver los nombres de los otros nodos, facilitando la comunicación entre ellos en el clúster.
- Finalmente, cambia el nombre del host del nodo
master(o el nodo correspondiente):
sudo hostnamectl set-hostname master
Configuración de Hadoop:
Navega al directorio principal del usuario y edita el archivo .bashrc para configurar las variables de entorno necesarias para Java y Hadoop. Abre el archivo con el editor de texto vim:
cd ~
vim ~/.bashrc
Agrega las siguientes líneas al final del archivo .bashrc:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=$HOME/hadoop-3.3.2
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
Estas líneas configuran la variable de entorno JAVA_HOME para Java y HADOOP_HOME para la instalación de Hadoop, además de agregar los binarios de Hadoop al PATH.
Aplica los cambios en las variables de entorno:
source ~/.bashrc
Clona el repositorio con la configuración de Hadoop desde GitHub:
git clone https://github.com/nilesh-g/hadoop-cluster-install.git
Copia los archivos de configuración de Hadoop desde el repositorio clonado al directorio de configuración de Hadoop:
cp hadoop-cluster-install/master/* $HADOOP_HOME/etc/hadoop/
Examinar la configuración del nodo master
Navega al directorio de configuración de Hadoop:
cp $HADOOP_HOME/etc/hadoop/
Examina los archivos de configuración para verificar y ajustar las configuraciones necesarias de Hadoop. Utiliza vim o cualquier otro editor para abrir los siguientes archivos:
vim core-site.xml
vim hadoop-env.sh
vim hdfs-site.xml
vim mapred-site.xml
vim yarn-site.xml
vim workers
core-site.xml: Configura las propiedades básicas de Hadoop, como el sistema de archivos.hadoop-env.sh: Verifica las variables de entorno, comoJAVA_HOME.hdfs-site.xml: Verifica la configuración del sistema de archivos distribuido (HDFS).mapred-site.xml: Revisa las configuraciones de MapReduce.yarn-site.xml: Verifica la configuración de YARN y el ResourceManager.workers: Contiene la lista de los nodos worker en el clúster.
Reinicia la máquina:
init 0
Crear clones vinculados para los workers:
Worker 1
Crea un clon vinculado de la máquina virtual actual (la que has configurado como nodo "master") en VirtualBox.
- Haz clic derecho sobre la máquina virtual en Virtualbox
- Selecciona "Clonar"

- Asigna el nombre "worker1" a la nueva máquina virtual y cambia la política de dirección MAC a: Generar nuevas direcciones MAC para todos los adaptadores de red:

- Elige la opción "Clon Vinculado" para crear una nueva máquina que comparta los discos con la original.

Estos pasos para clonar la máquina virtual vinculada se utilizarán como base para crear los demás nodos worker del clúster.
Enciende la nueva maquina clonada (worker1) e inicia sesión con "hduser".
Configura la red con la dirección IP estática
- Abre el archivo de configuración de netplan:
sudo vim /etc/netplan/01-netcfg.yaml
- Modificar el archivo para asignar la dirección IP estática de la máquina
worker1(para nuestro ejemplo,192.168.204.51):
network:
version: 2
renderer: networkd
ethernets:
enp0s3:
dhcp4: true
enp0s8:
addresses: [192.168.204.51/24]
dhcp4: false
- Aplica a configuración de red:
sudo netplan apply
- Verifica que la IP se haya asignado correctamente:
sudo ip a
- Establecer el nombre del host como
worker1:
sudo hostnamectl set-hostname worker1
- Ve al directorio home y copia los archivos de configuración especificaos para el nodo worker desde el repositorio al directorio de configuración de Hadoop:
cd ~
cp hadoop-cluster-install/worker/* $HADOOP_HOME/etc/hadoop/
Examina los archivos de configuración del nodo worker. Utiliza el editor vim para abrir cada archivo y verificar que todo esté configurado correctamente:
vim core-site.xml vim hadoop-env.sh vim hdfs-site.xml vim mapred-site.xml vim yarn-site.xml
Reiniciar la máquina virtual para aplicar cualquier cambio significativo:
init 0
Worker 2:
Ahora que ya sabes como clonar la maquina virtual con las características de Clon Vinculado, clona una nueva máquina virtual y llámala "worker2".
Enciende la nueva maquina clonada (worker2) e inicia sesión con "hduser".
Configura la red con la dirección IP estática
- Abre el archivo de configuración de netplan:
sudo vim /etc/netplan/01-netcfg.yaml
- Modificar el archivo para asignar la dirección IP estática de la máquina
worker2(para nuestro ejemplo,92.168.204.52):
network:
version: 2
renderer: networkd
ethernets:
enp0s3:
dhcp4: true
enp0s8:
addresses: [192.168.204.52/24]
dhcp4: false
- Aplica a configuración de red:
sudo netplan apply
- Verifica que la IP se haya asignado correctamente:
sudo ip a
- Establecer el nombre del host como
worker2:
sudo hostnamectl set-hostname worker2
- Ve al directorio home y copia los archivos de configuración especificaos para el nodo worker desde el repositorio al directorio de configuración de Hadoop:
cd ~
cp hadoop-cluster-install/worker/* $HADOOP_HOME/etc/hadoop/
Reiniciar la máquina virtual para aplicar cualquier cambio significativo:
init 0
Worker 3:
Ahora que ya sabes como clonar la maquina virtual con las características de Clon Vinculado, clona una nueva máquina virtual y llámala "worker3".
Enciende la nueva maquina clonada (worker3) e inicia sesión con "hduser".
Configura la red con la dirección IP estática
- Abre el archivo de configuración de netplan:
sudo vim /etc/netplan/01-netcfg.yaml
- Modificar el archivo para asignar la dirección IP estática de la máquina
worker3(para nuestro ejemplo,192.168.204.53):
network:
version: 2
renderer: networkd
ethernets:
enp0s3:
dhcp4: true
enp0s8:
addresses: [192.168.204.53/24]
dhcp4: false
- Aplica a configuración de red:
sudo netplan apply
- Verifica que la IP se haya asignado correctamente:
sudo ip a
- Establecer el nombre del host como
worker3
sudo hostnamectl set-hostname worker3
- Ve al directorio home y copia los archivos de configuración especificaos para el nodo worker desde el repositorio al directorio de configuración de Hadoop:
cd ~
cp hadoop-cluster-install/worker/* $HADOOP_HOME/etc/hadoop/
Reiniciar la máquina virtual para aplicar cualquier cambio significativo:
init 0
Verificación del Clúster Hadoop: Inicio, Pruebas
Inicia todas las máquinas virtuales:
En el nodo master, genera una clave SSH sin contraseña, y luego copia la clave generada al nodo master y a los nodos worker para asegurar que el nodo master pueda acceder a sí mismo y a los nodos worker sin necesidad de introducir una contraseña:
- Generar una clave SSH en el nodo master para permitir el acceso sin necesidad de contraseña:
master terminal> ssh-keygen -t rsa -P ""
- Copiar la clave SSH al nodo master para que el nodo master pueda acceder a sí mismo sin contraseña:
master terminal> ssh-copy-id hduser@master
- Copiar la clave SSH a cada uno de los nodos worker (worker1, worker2, worker3) para que el nodo master pueda acceder a ellos sin necesidad de contraseña:
master terminal> ssh-copy-id hduser@worker1
master terminal> ssh-copy-id hduser@worker2
master terminal> ssh-copy-id hduser@worker3
Inicia Hadoop y verifica:
master terminal> hdfs namenode -format
master terminal> start-dfs.sh
master terminal> start-yarn.sh
master terminal> jps
worker1 terminal> jps
worker2 terminal> jps
worker3 terminal> jps
Si te da error con la versión del jdk al momento de poner hdfs namenode -format:
Entra en la siguiente ruta y actualiza de la versión 8 a la 11:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Ahora para actualizar los workers con el siguiente comando:
worker1 terminal > scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh
worker2 terminal > scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh
worker3 terminal > scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Ya puedes acceder desde tu maquina local con el navegador en la dirección ip: http://192.168.204.50:9870
Puedes Verificar que funcione agregando contenido al hdfs así:
master terminal> echo "Welcome to Hadoop cluster" > hello.txt
master terminal> hadoop fs -put hello.txt /
master terminal> hadoop fs -ls /
master terminal> hadoop fs -cat /hello.txt
Verifica todo en el navegador:
No te olvides de apagar todas las maquinas virtuales.