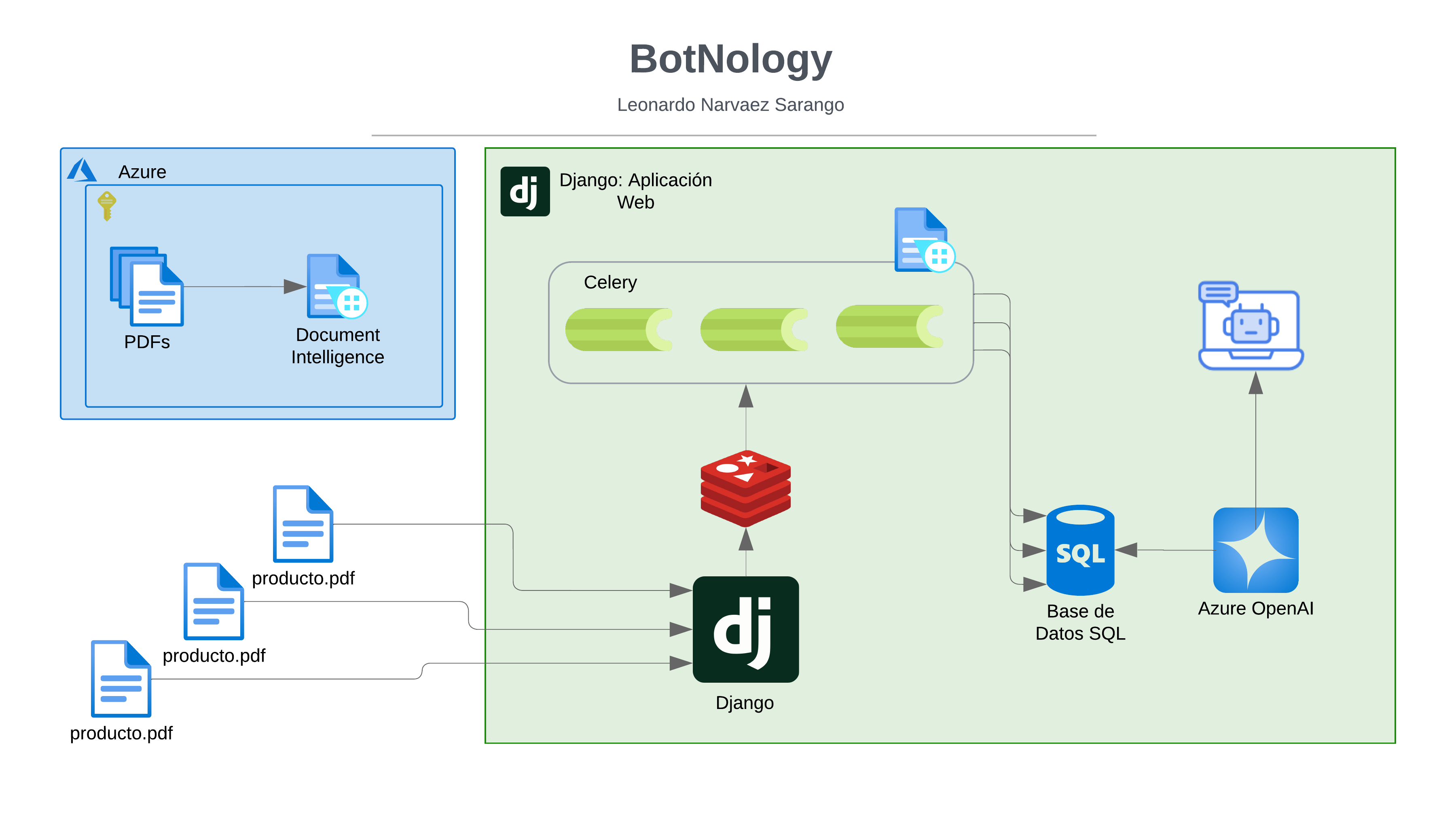
Introducción:
En este post, te mostraré cómo configurar Apache Spark en un contenedor Docker, con soporte para PySpark, Scala y SQL. Esta configuración te permitirá aprovechar la potencia de Spark para el procesamiento de grandes volúmenes de datos de manera flexible y escalable, todo dentro de un entorno controlado y fácil de gestionar. Ya sea que prefieras trabajar con Python, Scala o SQL, este contenedor ofrece una solución rápida y eficiente para ejecutar Spark en cualquier máquina, sin necesidad de instalaciones complicadas o conflictos de dependencias.
¿Qué incluye este contenedor?
Este contenedor Docker proporciona un entorno listo para usar con Apache Spark, soportando las siguientes tecnologías:
- Apache Spark: Framework de procesamiento de datos distribuido y de código abierto.
- Scala: Lenguaje funcional y orientado a objetos compatible con Spark.
- PySpark: Interfaz de Python para Spark, permitiendo escribir código en Python para el procesamiento distribuido.
- SQL: Soporte completo para ejecutar consultas SQL sobre grandes volúmenes de datos.
Requisitos previos
Antes de empezar, asegúrate de cumplir con los siguientes requisitos:
- Docker: Debes tener Docker instalado en tu máquina. Si no lo tienes, puedes seguir la guía de instalación oficial de Docker.
- Red interna de Docker: Asegúrate de poder crear redes internas en Docker, ya que es necesario para configurar la red entre contenedores (en este caso, para el contenedor
spark-master). - Conexión a Internet: Asegúrate de tener acceso a Internet para descargar las imágenes de Docker necesarias.
- Espacio en disco: Ten suficiente espacio en disco para ejecutar contenedores, ya que los contenedores de Spark pueden consumir varios gigabytes dependiendo de la carga de trabajo.
Sugerencia sobre la gestión de contenedores e imágenes
Es recomendable apagar y eliminar contenedores o imágenes que ya no necesites para evitar conflictos o el uso innecesario de recursos del sistema. Aquí tienes algunos comandos útiles para gestionarlos:
- Ver contenedores en ejecución:
docker ps
- Detener un contenedor: Si necesitas detener un contenedor en ejecución, puedes hacerlo con:
docker stop <nombre_contenedor>
- Eliminar un contenedor detenido: Después de detener un contenedor, puedes eliminarlo para liberar recursos:
docker rm <nombre_contenedor>
- Ver imágenes descargadas: Para ver las imágenes descargadas en tu sistema:
docker images
- Eliminar una imagen no utilizada: Si ya no necesitas una imagen, puedes eliminarla para liberar espacio en disco:
docker rmi <nombre_imagen>
- Eliminar contenedores e imágenes no utilizados de forma automática: Para eliminar todos los contenedores detenidos y las imágenes no utilizadas, puedes usar:
docker system prune
Nota: Este comando eliminará todo lo que no esté en uso, incluidos los contenedores detenidos, las redes no utilizadas y las imágenes no etiquetadas.
Realizar estas tareas de mantenimiento regularmente puede ayudarte a evitar conflictos o problemas de rendimiento en tu sistema.
Instalación de Apache Spark
A continuación, te guiaré a través de los pasos para instalar y ejecutar el contenedor con Apache Spark.
1. Crear una red de Docker
Primero, crea una red para que los contenedores puedan comunicarse entre sí.
docker network create spark-network
Confirma que la red se ha creado correctamente con:
docker network ls
Verás spark-network en la lista de redes disponibles.

2. Ejecutar el contenedor spark-master
Para ejecutar el contenedor con Apache Spark en modo master, usa el siguiente comando:
docker run -d --name spark-master --network spark-network -p 8080:8080 -p 7077:7077 -e SPARK_MODE=master -e SPARK_MASTER_HOST=spark-master bitnami/spark:3.2.1
Nota: Si te da error en los puertos 8080:8080 asegúrate que los puertos estén disponibles o intenta con cambiar los puertos por otro diferente hasta poder ejecutar el comando.
Para ver los contenedores en ejecución, usa el siguiente comando:
docker ps

Accede a la interfaz web de Spark en tu navegador visitando http://localhost:8080.

Uso del contenedor
Ahora que tienes Apache Spark ejecutándose, puedes empezar a trabajar con PySpark, Scala y SQL. Aquí te muestro cómo acceder a cada uno:
1. Acceder al contenedor con una terminal interactiva
Puedes acceder al contenedor con el siguiente comando:
docker exec -it spark-master /bin/bash
Ahora estaremos dentro de la terminal de nuestro contenedor

2. Iniciar PySpark
Para iniciar PySpark, simplemente ejecuta:
pyspark

Ahora tienes acceso a PySpark. Si quieres salir de la terminal, pulsa: Ctrl + D.
3. Iniciar Spark con Scala
Para iniciar Spark con Scala, ejecuta:
spark-shell

Ahora tienes acceso a PySpark. Si quieres salir de la terminal, pulsa: Ctrl + D.
4. Ejecutar SQL en Spark
Para ejecutar consultas SQL en Spark, usa:
/opt/bitnami/spark/bin/spark-sql --master spark://spark-master:7077

Ahora tienes acceso a PySpark. Si quieres salir de la terminal, pulsa: Ctrl + D.
5. Ejecutar JAVA:
Verificamos la versión de java.
java -version
 Ahora vamos a probar java con un
Ahora vamos a probar java con un HelloWord
echo 'public class HelloWorld { public static void main(String[] args) { System.out.println("Hello, Spark and Java!"); } }' > HelloWorld.java
Compilamos el archivo HelloWorld:
javac HelloWorld.java
Ejecutamos el programa:
java HelloWorld
Ahora ya tendremos disponible java para la ejecución de nuestros programas, para salir de la terminal pulsa: ctrl + d.

Finalizar
Cuando termines de trabajar con el contenedor, puedes detenerlo y eliminarlo de la siguiente manera:
- Detener el contenedor:
docker stop spark-master
- Eliminar el contenedor:
docker rm spark-master
Conclusión
Este repositorio proporciona una solución rápida y sencilla para ejecutar Apache Spark en un contenedor Docker, con soporte para PySpark, Scala y SQL. Gracias a Docker, puedes trabajar en un entorno aislado y reproducible, sin preocuparte por configuraciones complejas o conflictos de dependencias. Recuerda también gestionar adecuadamente los contenedores e imágenes para mantener tu sistema limpio y eficiente.