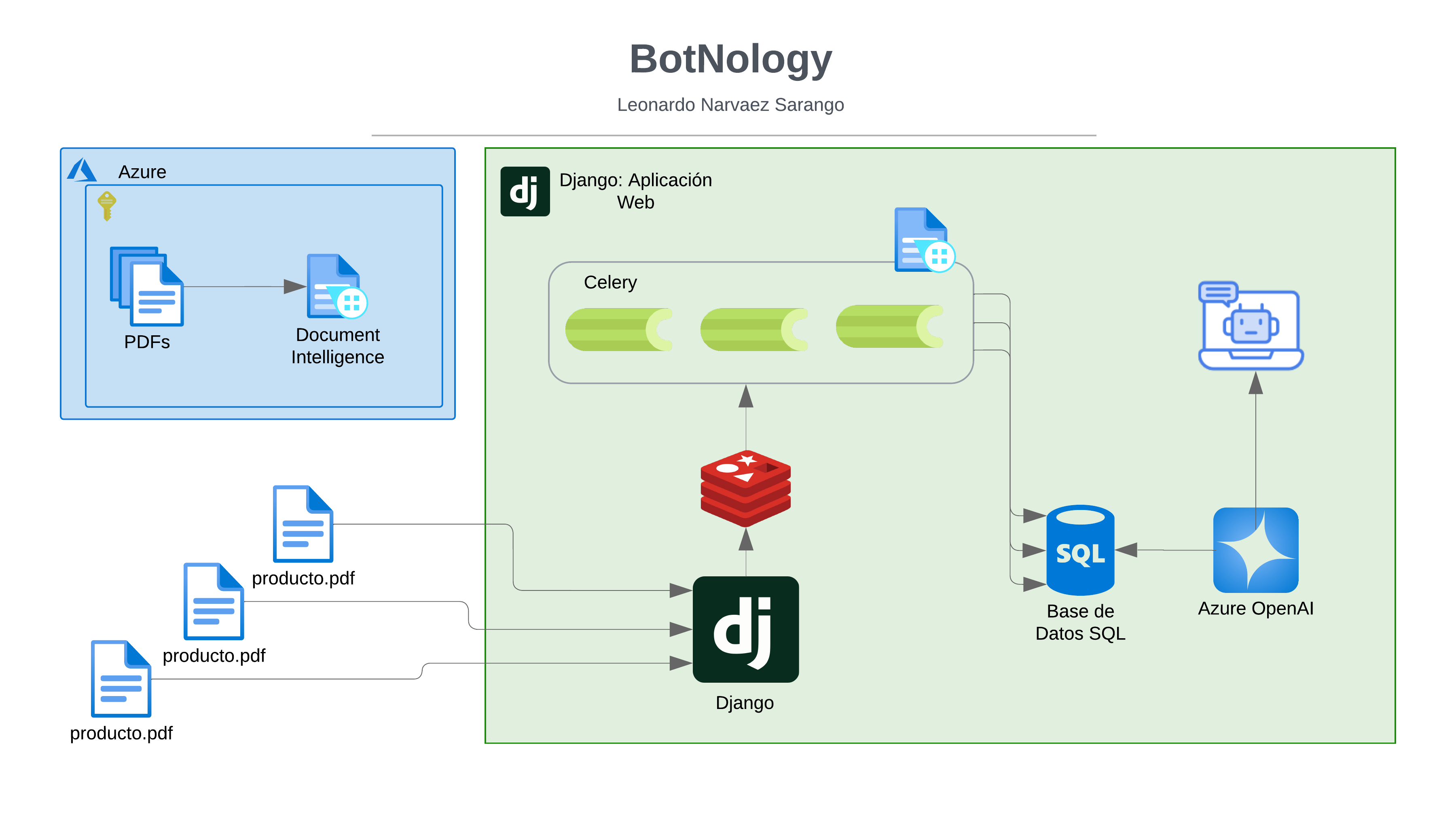
Spark JDBC
En el corazón de la integración de Spark con bases de datos relacionales encontramos JDBC (Java Database Connectivity). JDBC actúa como un puente esencial, proporcionando una interfaz estandarizada que permite a las aplicaciones Spark comunicarse con bases de datos relacionales. Esta interfaz no es simplemente un canal de comunicación; es un conjunto completo de protocolos y estándares que facilitan operaciones de lectura y escritura de manera eficiente y segura.
Spark SQL y su Relación con JDBC
Spark SQL emerge como uno de los módulos más poderosos dentro del ecosistema Spark. Este módulo introduce el concepto de DataFrames, una abstracción que permite trabajar con datos estructurados de manera intuitiva y eficiente. Cuando combinamos Spark SQL con JDBC, obtenemos una herramienta extremadamente versátil para el procesamiento de datos.
La integración de Spark SQL con JDBC va más allá de simples operaciones de lectura y escritura. El sistema permite ejecutar consultas complejas que se benefician del procesamiento distribuido de Spark, mientras mantiene la integridad y las características ACID de las bases de datos relacionales. Esta simbiosis permite aprovechar lo mejor de ambos mundos: la escalabilidad de Spark y la confiabilidad de las bases de datos relacionales.
Arquitectura
La arquitectura de la integración Spark-JDBC se construye sobre varios componentes fundamentales que trabajan en conjunto. El Driver JDBC actúa como el intérprete principal, traduciendo las instrucciones de Spark en comandos que la base de datos puede entender. Este componente maneja no solo la traducción de comandos, sino también la gestión de tipos de datos y la optimización de consultas.
El Connection Pool representa otro componente crucial en esta arquitectura. En lugar de crear nuevas conexiones para cada operación, mantiene un conjunto de conexiones activas que pueden ser reutilizadas. Este enfoque reduce significativamente la sobrecarga asociada con el establecimiento de conexiones y mejora el rendimiento general del sistema.
El sistema de particionamiento en esta arquitectura merece especial atención. Permite dividir grandes conjuntos de datos en fragmentos manejables que pueden procesarse en paralelo. Este particionamiento no es arbitrario; se basa en estrategias sofisticadas que consideran la distribución de datos y los recursos disponibles.
Operaciones y Optimización
Las operaciones en el contexto de Spark-JDBC pueden clasificarse en tres categorías principales: lectura, escritura y transformación. Las operaciones de lectura pueden variar desde la simple recuperación de tablas completas hasta consultas complejas con múltiples joins y agregaciones. La escritura, por otro lado, puede implicar inserciones masivas, actualizaciones o operaciones de upsert.
La optimización en este contexto es un arte complejo. El push-down de predicados representa una de las técnicas más importantes, permitiendo que los filtros se ejecuten en la base de datos antes de que los datos se transfieran a Spark. Esto puede reducir significativamente la cantidad de datos transferidos y mejorar el rendimiento general.
La gestión de recursos y la configuración de parámetros juegan un papel crucial en el rendimiento. El tamaño del fetch, el número de particiones y el tamaño del batch deben ajustarse cuidadosamente según las características específicas de cada caso de uso. Estos ajustes pueden tener un impacto significativo en el rendimiento y la utilización de recursos.
Ejemplo de conexión de JDBC desde Databricks Community con SQL Server de Azure.
Creación de SQL Server en Azure
Crear un grupo de recursos. Luego crear un recurso > Bases de datos > SQL Database

Configura los detalles:
- Nombre del servidor SQL: databricks-sql-server-leo
- Región: Italy North u otra disponible
- Autenticación: Habilita SQL Authentication y configura:
Usuario: adminuser
Contraseña: ContraseñaFuerte123

- Marca la casilla de "Habilitar acceso a Azure Services"
Crear la base de datos: AdventureWorksLT
- En la misma sección, crea una base de datos con nombre cualquiera (en este ejemplo le hemos llamado database-sql). Selecciona el servidor creado (databricks-sql-server-leo).Nivel de precio: Elige el plan más económico (Básico - DTU: 5).

- En Additional settings, en Data Source escoger Sample para que se habilite la carga de AdventureWorksLT. Lo demas se deja por defecto.

- Ve al servidor que has creado y en networking configurar el firewall. Añade la IP pública de tu conexión local y habilita "Permitir acceso a todos los servicios de Azure". Habilita la dirección IP publica de databricks, suele ser: 54.200.13.2. Guarda los cambios.


Configurar Databricks Community Edition
Ve a la pestaña Compute y selecciona Create Compute con estos requisitos:
- Cluster Name: AdventureWorksCluster.
- Databricks Runtime Version: 11.3 LTS (Scala 2.12, Spark 3.3.1)
- Crear clúster.

Mientras el clúster se esta creando, descarga el controlador JDBC para SQL Server, en este caso usaremos este. O dentro del resositorio se encuentra dentro de la carpeta resources.
- En Databricks subir el controlador a tu workspace o a tu DBFS.

Una vez que el cluster esté activo ve al Cluster y en el boton Libraries cargar el controlador haciendo click en `Install New` y le pasas el path donde has guardado el controlador.


Conectar Databricks con SQL Server
Crea un notebook en Databricks y añade el siguiente código ( con tus datos de configuración) :
# Configuración de conexión JDBC
jdbcHostname = "databricks-sql-server-leo.database.windows.net" # Servidor SQL
jdbcPort = 1433
jdbcDatabase = "database-sql" # Nombre exacto de tu base de datos
jdbcUsername = "adminuser" # Cambiar por tu usuario configurado
jdbcPassword = "ContraseñaFuerte123" # Cambiar por la contraseña configurada
jdbcUrl = f"jdbc:sqlserver://{jdbcHostname}:{jdbcPort};databaseName={jdbcDatabase}"
# Propiedades de conexión
connectionProperties = {
"user": jdbcUsername,
"password": jdbcPassword,
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
Consulta de Prueba
# Consulta de prueba
query = "(SELECT TOP 10 * FROM SalesLT.Product) AS temp" # Cambia por una tabla válida si es necesario
# Leer datos desde SQL Server
try:
df = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
df.display() # Mostrar los datos
except Exception as e:
print(f"Error al conectar: {e}")
Si te da fallo de IP, debe ser por que no esta configurado correctamente las reglas de firewall, usa el siguiente comando y el resultado de esa IP debes actualizarlo en las reglas de firewall de tu servidor
import requests
# Obtener la IP pública del nodo
public_ip = requests.get('https://api.ipify.org').text
print(f"La IP pública del nodo es: {public_ip}")


Vuelve a ejecutar el comando anterior de la consulta y veras ya conectado con la base de datos configurada en Azure.

Prueba con consultas simples usando Pyspark:
1. Listar todas las tablas disponibles
query = "(SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE') AS temp"
df_tables = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
df_tables.show()

2. Productos con precios mayores a $50
query = "(SELECT ProductID, Name, ListPrice FROM SalesLT.Product WHERE ListPrice > 50) AS temp"
df_filtered = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
df_filtered.show()

3. Contar productos por categoría
query = """
(SELECT ProductCategoryID, COUNT(*) AS TotalProducts
FROM SalesLT.Product
GROUP BY ProductCategoryID) AS temp
"""
df_count = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
df_count.show()

- Ordenamos los datos con Spark.
query = """
(SELECT ProductCategoryID, COUNT(*) AS TotalProducts
FROM SalesLT.Product
GROUP BY ProductCategoryID) AS temp
"""
# Ordenar los resultados en Spark
df_count_sorted = df_count.orderBy("TotalProducts", ascending=False)
df_count_sorted.display()

4. Contar el total de productos por tamaño
df.groupBy("Size").count().orderBy("count", ascending=False).show()

- Hacer algunas mejoras a la consulta:
from pyspark.sql.functions import desc
df.filter(df["Size"].isNotNull()) \
.groupBy("Size") \
.count() \
.withColumnRenamed("count", "TotalCount") \
.orderBy(desc("TotalCount")) \
.display()

5. Calcular el precio promedio de los productos
df.selectExpr("AVG(ListPrice) AS AveragePrice").show()

- Vamos mejorar nuestra consulta, mostrando más información con el nombre del producto, realizamos agrupaciones para facilitar la consulta. Ahora calculamos el precio promedio por producto y agregamos el nombre.
from pyspark.sql.functions import round
df.groupBy("ProductID", "Name") \
.agg({"ListPrice": "avg"}) \
.withColumnRenamed("avg(ListPrice)", "AveragePrice") \
.withColumn("AveragePrice", round("AveragePrice", 2)) \
.display()

6. Encontrar productos sin categoría asignada
df.filter(df.ProductCategoryID.isNull()).select("ProductID", "Name", "ProductCategoryID").show()

Comprobamos porque esta consulta no nos muestra ningún resultado:
# Verificar si hay registros con ProductCategoryID nulo
count_nulls = df.filter(df.ProductCategoryID.isNull()).count()
print(f"Registros con ProductCategoryID NULL: {count_nulls}")
# Verificar los registros con ProductCategoryID NULL
if count_nulls > 0:
print("Registros con ProductCategoryID NULL:")
df.filter(df.ProductCategoryID.isNull()).select("ProductID", "Name", "ProductCategoryID").display()
else:
print("No hay registros con ProductCategoryID NULL.")
# Verificar si hay registros con ProductCategoryID no nulo
count_non_nulls = df.filter(df.ProductCategoryID.isNotNull()).count()
print(f"Registros con ProductCategoryID NO NULL: {count_non_nulls}")
# Verificar los registros con ProductCategoryID no nulo
if count_non_nulls > 0:
print("Registros con ProductCategoryID NO NULL:")
df.filter(df.ProductCategoryID.isNotNull()).select("ProductID", "Name", "ProductCategoryID").display()
else:
print("No hay registros con ProductCategoryID NO NULL.")

7. Contar productos por color
df.groupBy("Color").count().orderBy("count", ascending=False).show()

8. Calcular el costo total de todos los productos
df.selectExpr("SUM(StandardCost) AS TotalCost").show()

Vamos a mejorar la query anterior, mostrando el total por categoría y ordenando según el costo total.
from pyspark.sql.functions import round
df.groupBy("ProductCategoryID").agg({"StandardCost": "sum"}) \
.withColumnRenamed("sum(StandardCost)", "TotalCost") \
.withColumn("TotalCost", round("TotalCost", 2)) \
.orderBy(desc("TotalCost")) \
.display()

9. Productos que contienen una palabra específica en su nombre
# Filtrar productos que contienen la palabra 'Helmet' en el nombre
df.filter(df.Name.contains("Helmet")).select("ProductID", "Name", "ListPrice").show()

Listamos los nombres de todos los productos
df.select("Name").display()

10. Listar productos creados después de 2005
df.filter(df.SellStartDate >= "2005-01-01").select("ProductID", "Name", "SellStartDate").show()

11. Producto más caro por categoría
from pyspark.sql.functions import col, max as spark_max
df.groupBy("ProductCategoryID").agg(spark_max("ListPrice").alias("MaxPrice")).orderBy("MaxPrice", ascending=False).show()

12. Calcular el precio promedio por categoría
from pyspark.sql.functions import avg
df.groupBy("ProductCategoryID").agg(avg("ListPrice").alias("AveragePrice")).orderBy("AveragePrice", ascending=False).show()

Redondeamos el precio, ordenamos y mostramos mas ordenado.
df.groupBy("ProductCategoryID") \ .agg(avg("ListPrice").alias("AveragePrice")) \ .withColumn("AveragePrice", round(col("AveragePrice"), 2)) \ .filter(col("AveragePrice") > 50) \ .orderBy(col("AveragePrice").desc()) \ .display()

13. Encontrar productos descontinuados (Discontinued no es NULL)
df.filter(df.DiscontinuedDate.isNotNull()).select("ProductID", "Name", "DiscontinuedDate").show()

14. Productos con precios mayores que su costo estándar
df.filter(df.ListPrice > df.StandardCost).select("ProductID", "Name", "ListPrice", "StandardCost").show()

Actividad 1:
Repetir las consultas anteriores pero usando SQL (no pyspark)
Registrar las tablas que utilizarás como tabla temporal, por ejemplo:
query = "(SELECT * FROM SalesLT.Product) AS temp"
df = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
df.createOrReplaceTempView("Product")
%sql
SELECT ProductID, Name, ListPrice
FROM Product
ORDER BY ListPrice DESC
LIMIT 5;

Ahora todas las consultas las realizamos con SQL y las guardamos dentro del notebook_sql
Actividad.
La Empresa decide "migrar" de sql server a postgreSQL. Efectuar la conexion Databricks Community con PostgreSQL en Azure. Efectuar algunas consultas sobre PostgreSQL usando PySpark y Scala. Utiliza una base de datos cualquiera.
Si la version de community da muchos problemas utilizar Azure Databricks.
Creación de PosgreSQL en Azure
- Crear un grupo de recursos. Luego crear un recurso > Bases de datos > Azure PostgreSQL
- Configura los detalles:
- Nombre del sesrvidor SQL: `databricks-postgresq-leo`
- Región: Italy North u otra disponible
- Autenticación: Habilita SQL Authentication y configura:
1. Usuario: adminuser
2. Contraseña: ContrasenaFuerte123
- Marca la casilla de "Habilitar acceso a Azure Services"
- En el portal busca Bases de Datos y crea una con el nombre: `db_postgresql`
import requests
# Obtener la IP pública del nodo
public_ip = requests.get('https://api.ipify.org').text
print(f"La IP pública del nodo es: {public_ip}")
Configurar Databricks Community Edition
Ve a la pestaña Computey selecciona Create Compute con estos requisitos:
- Cluster Name: PSQL_Cluster.
- Databricks Runtime Version: 11.3 LTS (Scala 2.12, Spark 3.3.1)
- Crear clúster.
- Mientras el clúster se esta creando, descarga el controlador JDBC para SQL Server, en este caso usaremos [este](https://jdbc.postgresql.org/download/).
- En Databricks subir el controlador a tu workspace o a tu DBFS.
- Una vez que el cluster esté activo ve al Cluster y en el boton Libraries cargar el controlador haciendo click en `Install New` y le pasas el path donde has guardado el controlador.
# Configuración de conexión JDBC
jdbcHostname = "databricks-postgresq-leo.postgres.database.azure.com" # Servidor SQL
jdbcPort = 5432
jdbcDatabase = "db_postgresql" # Nombre exacto de tu base de datos
jdbcUsername = "adminuser" # Cambiar por tu usuario configurado
jdbcPassword = "ContrasenaFuerte123" # Cambiar por la contraseña configurada
jdbcUrl = f"jdbc:postgresql://{jdbcHostname}:{jdbcPort}/{jdbcDatabase}?sslmode=require"
# Propiedades de conexión
connectionProperties = {
"user": jdbcUsername,
"password": jdbcPassword,
"driver": "org.postgresql.Driver"
}
try:
# Intentar realizar la consulta
query = "(SELECT table_name FROM information_schema.tables WHERE table_schema = 'public') AS tables"
df_tables = spark.read.jdbc(url=jdbcUrl, table=query, properties=connectionProperties)
# Mostrar las tablas
df_tables.show()
except Exception as e:
print("Error de conexión:", e)
Paso 1: Crear la tabla con un DataFrame y escribir en PostgreSQL
Aunque PySpark no tiene un método directo para ejecutar comandos como `CREATE TABLE`, puedes crear un DataFrame y escribir los datos directamente a una tabla de PostgreSQL. Si la tabla no existe, PySpark la creará automáticamente.
import psycopg2
# Establecer la conexión con PostgreSQL
conn = psycopg2.connect(
host=jdbcHostname,
port=jdbcPort,
dbname=jdbcDatabase,
user=jdbcUsername,
password=jdbcPassword
)
# Crear un cursor para ejecutar la consulta SQL
cursor = conn.cursor()
# Consulta SQL para crear la tabla
create_table_query = """
CREATE TABLE IF NOT EXISTS products (
ProductID SERIAL PRIMARY KEY,
ProductName VARCHAR(100),
Category VARCHAR(50),
Price DECIMAL(10, 2),
StockQuantity INT
);
"""
# Ejecutar la consulta de creación de tabla
cursor.execute(create_table_query)
# Confirmar los cambios
conn.commit()
# Cerrar el cursor y la conexión
cursor.close()
conn.close()
print("Tabla creada con éxito.")
Paso 2: Escribir el DataFrame en PostgreSQL
Usando el método `df.write.jdbc()`, puedes escribir los datos del DataFrame en PostgreSQL. Si la tabla no existe, PySpark la crea automáticamente. Si ya existe, puedes optar por reemplazar los datos o agregar nuevos registros.
from pyspark.sql import Row
# Crear datos de ejemplo para los productos
product_data = [
Row(ProductName="Laptop", Category="Electronics", Price=799.99, StockQuantity=50),
Row(ProductName="Smartphone", Category="Electronics", Price=499.99, StockQuantity=200),
Row(ProductName="Table", Category="Furniture", Price=150.50, StockQuantity=30),
Row(ProductName="Headphones", Category="Electronics", Price=89.99, StockQuantity=150),
Row(ProductName="Coffee Maker", Category="Home Appliances", Price=120.00, StockQuantity=80)
]
# Convertir los datos en un DataFrame de PySpark
df_products = spark.createDataFrame(product_data)
# Insertar los datos en la tabla "products" de PostgreSQL
df_products.write.jdbc(url=jdbcUrl, table="products", mode="append", properties=connectionProperties)
print("Datos insertados con éxito.")
Paso 3: Esquema de la tabla
PySpark crea la tabla con el esquema definido por el DataFrame. Las columnas del DataFrame serán las mismas que las de la tabla en PostgreSQL, asegurando que el esquema de datos esté alineado entre ambos sistemas.
# Leer los datos desde la tabla "products" en PostgreSQL
df_products_from_db = spark.read.jdbc(url=jdbcUrl, table="products", properties=connectionProperties)
# Mostrar los primeros registros
df_products_from_db.display()
Comprobamos, conectándonos en la base de datos por ssh y realizamos una consulta.![]