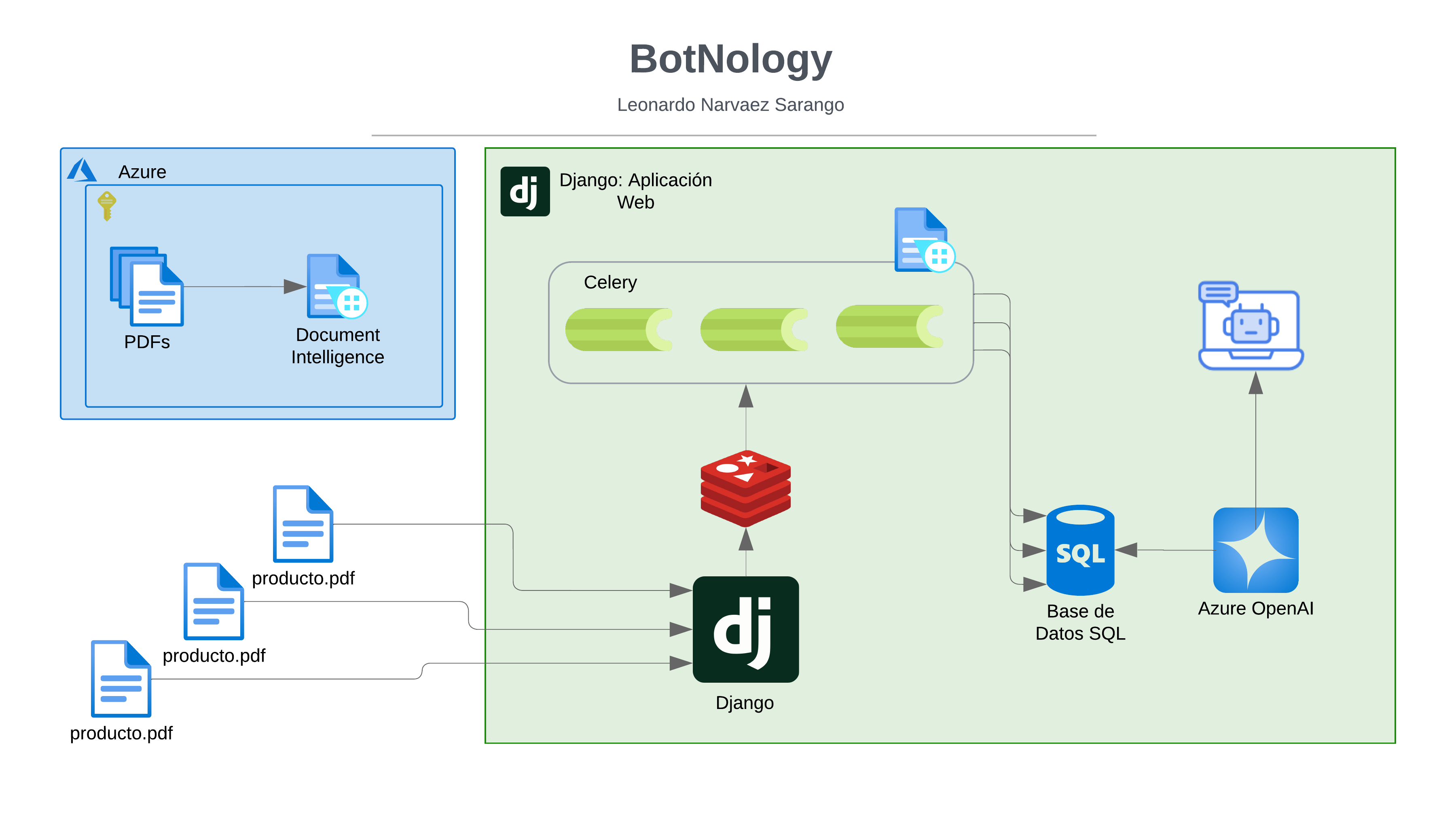
Descripción
Este repositorio contiene un tutorial completo sobre cómo comenzar con Azure Synapse Analytics, incluyendo la creación de un área de trabajo, la configuración de una cuenta de almacenamiento, la carga y análisis de datos utilizando SQL sin servidor y Apache Spark. Está diseñado para ayudar a los usuarios a familiarizarse con Azure Synapse y sus herramientas principales.
El tutorial esta basado en las guias de learn de microsoft aquí.
Contenidos
- Introducción a Azure Synapse Analytics: Conceptos básicos y requisitos previos.
- Creación del Área de Trabajo: Paso a paso sobre cómo crear un área de trabajo en Azure Synapse desde Azure Portal.
- Carga de Datos de Ejemplo: Instrucciones para cargar un conjunto de datos de ejemplo en el área de trabajo.
- Análisis de Datos con SQL Sin Servidor: Ejemplos de consultas SQL para explorar los datos cargados.
- Creación y Configuración de Grupos de Apache Spark: Cómsy
- Análisis de Datos con Spark: Ejecución de análisis de datos usando notebooks y Apache Spark.
Requisitos Previos
- Cuenta de Azure: Puedes crear una cuenta gratuita en Azure.
- Acceso a Azure Portal: Debes tener acceso al portal de Azure y permisos para crear recursos.
Cómo Empezar
Paso 1: Creación del Área de Trabajo de Synapse en Azure Portal
Abrir Azure Portal: Ve a Azure Portal y escribe "Synapse" en la barra de búsqueda sin pulsar enter.

Seleccionar Azure Synapse Analytics: En los resultados de búsqueda, bajo "Servicios", selecciona Azure Synapse Analytics.
Crear Área de Trabajo: Selecciona Crear para comenzar a crear un área de trabajo.
Datos Básicos:
- Suscripción: Selecciona la suscripción que tengas disponible.
- Grupo de recursos: Usa un grupo de recursos existente o crea uno nuevo.
- Grupo de recursos administrados: Déjalo en blanco.
- Nombre del área de trabajo: Ingresa un nombre que sea único. Por ejemplo:
myworkspaceai97. - Región: Selecciona la misma región donde se encuentran tus aplicaciones y servicios para evitar problemas de rendimiento. Nosotros seleccionamos
North Europe - En "Seleccionar Data Lake Storage Gen2": Nombre de la cuenta: Selecciona Crear nuevo y asigna un nombre único, por ejemplo,
accountname97. Importante recordad - Nombre del sistema de archivos: Selecciona Crear nuevo y asigna el nombre
users. - Marca la casilla para asignarte el rol de Colaborador de datos de Storage Blob.
Te debe quedar de la siguiente manera:

Revisar y crear:
Selecciona Revisar y crear y luego Crear.

Espera unos minutos hasta que el área de trabajo esté lista.

Paso 2: Abrir Synapse Studio
Abrir Synapse Studio desde Azure Portal: Una vez que el área de trabajo esté creada, ve a la sección "Información general" y selecciona Abrir en el cuadro Abrir Synapse Studio.

Iniciar sesión en Synapse Studio: Inicia sesión utilizando tu suscripción de Azure.

Paso 3: Cargar Datos de Ejemplo
Descargar el dataset de NYC Taxi: Descarga el dataset "NYC Taxi - green trip" en tu equipo desde el siguiente vínculo.
Cambia el nombre del archivo descargado a NYCTripSmall.parquet.

Cargar el archivo en Synapse Studio:
- Ve al centro Datos en Synapse Studio.

- Selecciona Vinculado y luego el contenedor llamado
users (Primary).

- Selecciona Cargar y sube el archivo
NYCTripSmall.parquet.

Paso 4: Análisis de Datos con un Grupo de SQL Sin Servidor
Crear un script de SQL: En Synapse Studio, ve al centro de Desarrollo y crea un nuevo script de SQL.

Ejecutar una consulta SQL: Pega el siguiente código en el script (actualiza accountname97 el nombre de tu cuenta de almacenamiento y users con el nombre del contenedor):
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://accountname97.dfs.core.windows.net/users/NYCTripSmall.parquet',
FORMAT='PARQUET'
) AS [result]
Selecciona Run (Ejecutar).

Paso 5: Creación de una Base de Datos de Exploración de Datos
Creamos un nuevo script SQL:

Crear una Base de Datos Independiente: Usa la base de datos master para crear una nueva base de datos denominada DataExplorationDB:
CREATE DATABASE DataExplorationDB
COLLATE Latin1_General_100_BIN2_UTF8
Importante: Usa una intercalación con sufijo_UTF8para que el texto UTF-8 se convierta correctamente en columnasVARCHAR.

Cambiar el Contexto de la Base de Datos: Cambia el contexto de la base de datos desde master a DataExplorationDB:
USE DataExplorationDB

Crear Objetos de Utilidad:
- Crea un origen de datos externo:
CREATE EXTERNAL DATA SOURCE ContosoLake
WITH ( LOCATION = 'https://accountname97.dfs.core.windows.net')
Nota: Los orígenes de datos externos se pueden crear sin credenciales.

Paso 6: Creación de un Grupo de Apache Spark Sin Servidor
- Crear un Grupo de Apache Spark:
- En Synapse Studio, en el lado izquierdo, selecciona Administrar > Grupos de Apache Spark.

- Selecciona Nuevo paso.
- En Nombre del grupo de Apache Spark escribe
Spark1. - En Tamaño del nodo escribe
Pequeño. - En Número de nodos, establece el valor mínimo en
3y el máximo en3.

- Selecciona Revisar y crear > Crear.

Paso 7: Análisis de Datos de Taxis de Nueva York con un Grupo de Spark
Crear un Nuevo Notebook: Crea un nuevo notebook en Synapse Studio y asocia el grupo de Spark Spark1.


Cargar y Mostrar Datos:
%%pyspark
df = spark.read.load('abfss://users@accountname97.dfs.core.windows.net/NYCTripSmall.parquet', format='parquet')
display(df.limit(10))

Ver el Esquema de la Trama de Datos:
%%pyspark df.printSchema()

Cargar los Datos en una Base de Datos de Spark:
%%pyspark
spark.sql("CREATE DATABASE IF NOT EXISTS nyctaxi")
df.write.mode("overwrite").saveAsTable("nyctaxi.trip")

Análisis de los Datos Mediante Spark y Notebooks:
%%pyspark
df = spark.sql("SELECT * FROM nyctaxi.trip")
display(df)

Guardar Resultados de Análisis:
%%pyspark
df = spark.sql("""
SELECT passenger_count,
SUM(trip_distance) as SumTripDistance,
AVG(trip_distance) as AvgTripDistance
FROM nyctaxi.trip
WHERE trip_distance > 0 AND passenger_count > 0
GROUP BY passenger_count
ORDER BY passenger_count
""")
display(df)
df.write.saveAsTable("nyctaxi.passengercountstats")

Conclusión
En este tutorial, hemos aprendido a:
- Crear un área de trabajo de Azure Synapse Analytics.
- Configurar una cuenta de almacenamiento y cargar datos.
- Utilizar un grupo de SQL sin servidor para analizar datos.
- Crear una base de datos de exploración de datos y objetos de utilidad.
- Configurar y utilizar un grupo de Apache Spark sin servidor.
- Realizar análisis de datos utilizando Apache Spark y notebooks.
Este es solo el comienzo. Puedes seguir explorando las herramientas disponibles en Synapse Studio, como la integración con Power BI para crear visualizaciones interactivas.